Testing your AKS resiliency with Chaos Studio
Posted on: August 26, 2024Azure Chaos Studio allows you to run chaos experiments on your Azure resources:
To get good understanding about chaos engineering and Chaos Studio, please check out this excellent presentation from Build 2024:
Improve Application Resilience using Azure Chaos Studio
The above presentation explains how you should approach chaos engineering implementation:
Formulate hypotheses around resiliency scenarios, craft and execute a fault injection experiment in a safe environment, monitor the impact, analyze results and make improvements.
In this post, I will show you how to use Chaos Studio to test the resiliency of your AKS cluster.
To get started, there are many safety mechanisms in-place for preventing accidental chaos experiments for your resources:
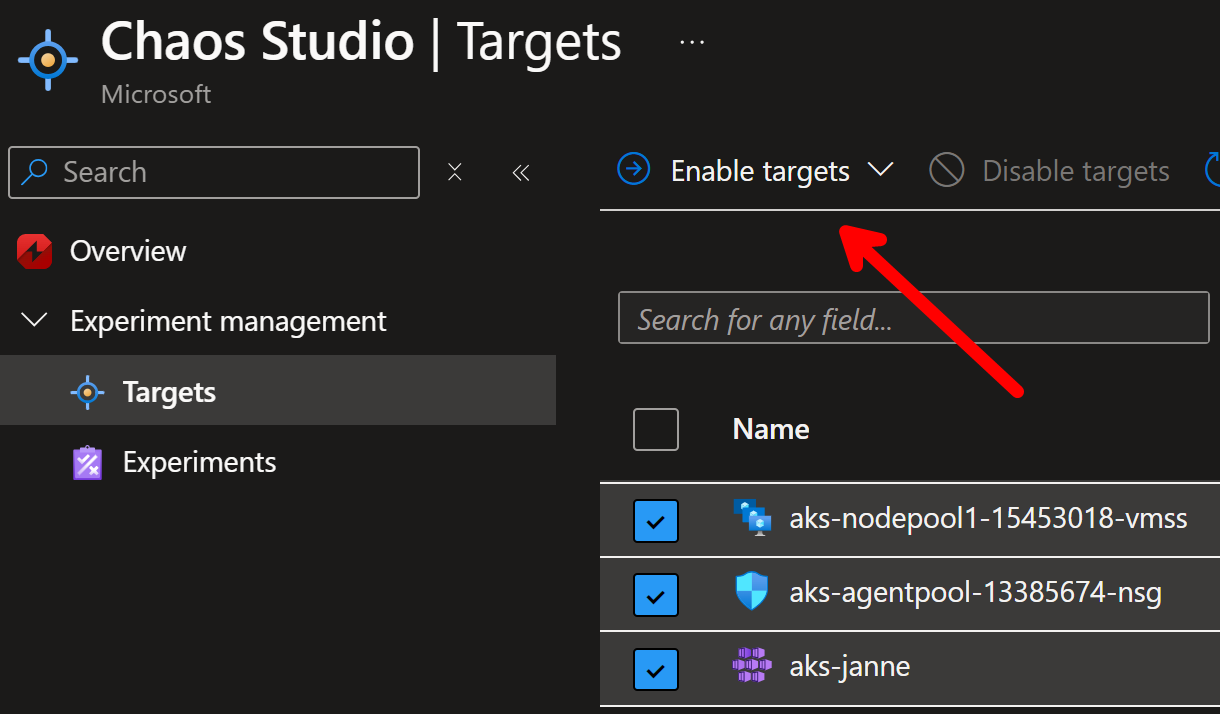
First, you need to enable Azure resources to be used with Chaos Studio:
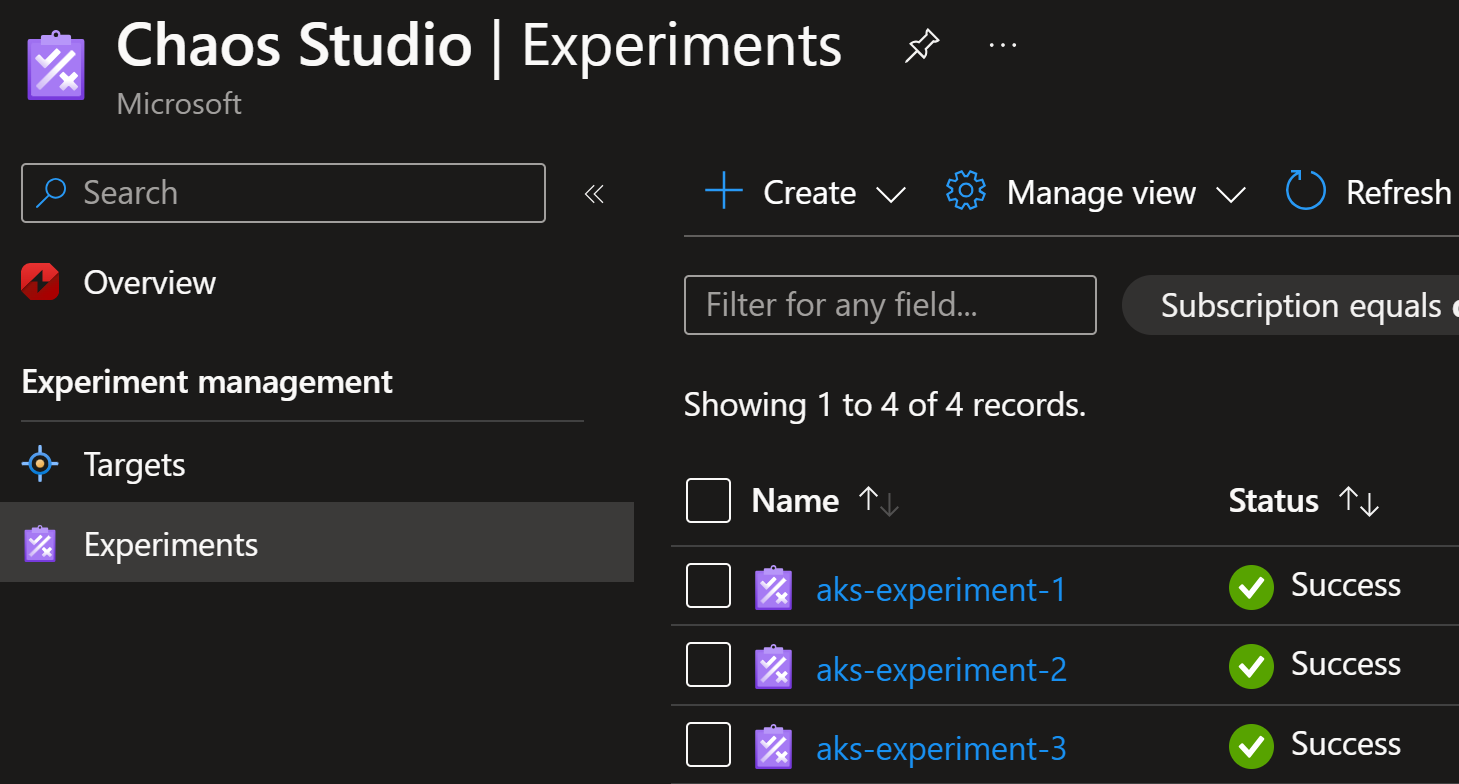
Then you can start creating experiments and connect them to these resources:
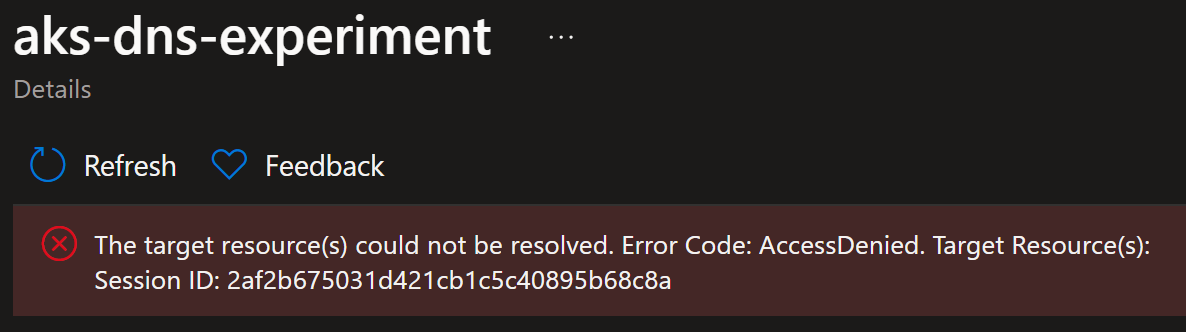
Next you need to enable the identity of the experiment to have required permissions to perform the configured tasks (e.g., shutdown VM, update NSG, etc.). Read more about Permissions and security in Azure Chaos Studio in the documentation.
Otherwise, you will get an error like this:
Additionally, when experimenting with AKS, you need to make sure that:
- Local accounts are not disabled in the cluster
- API server is accessible by the experiments
- You need to Set up Chaos Mesh on your AKS cluster
If you have local accounts disabled in your cluster, you’ll get the following error message when trying to run faults on the cluster:
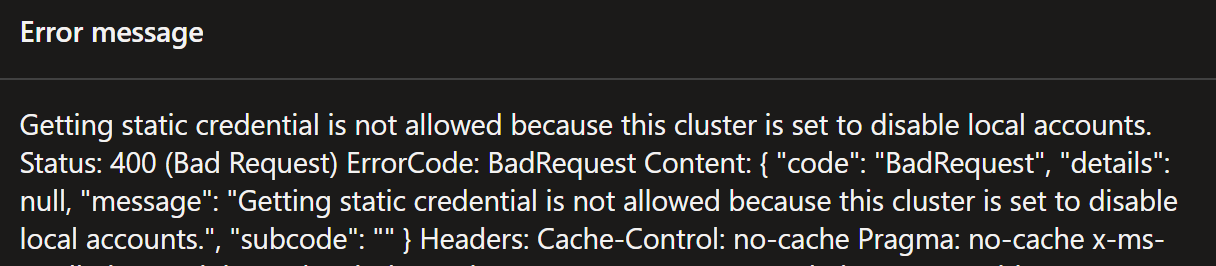
This is the error message if API server is not accessible by the experiments:

Okay, let’s start with some experiments!
Experiment 1: Simulate DNS failures
Let’s start with a simple, yet very effective experiment: simulate DNS failures. Here is our test application and its dependencies:
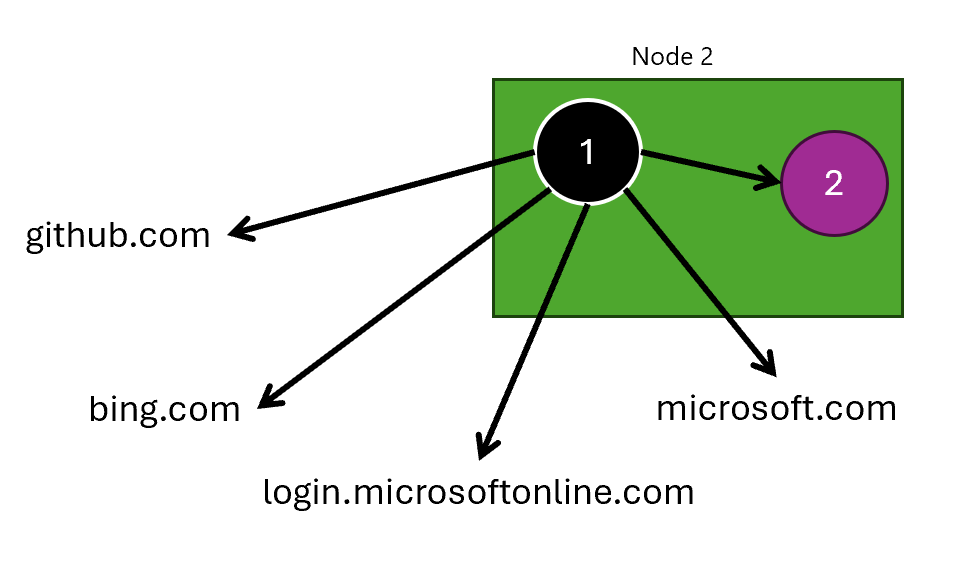
Our hypothesis is that our application continues to run, even if DNS is failing for some of the services.
We want to simulate following failure scenario with our app next:
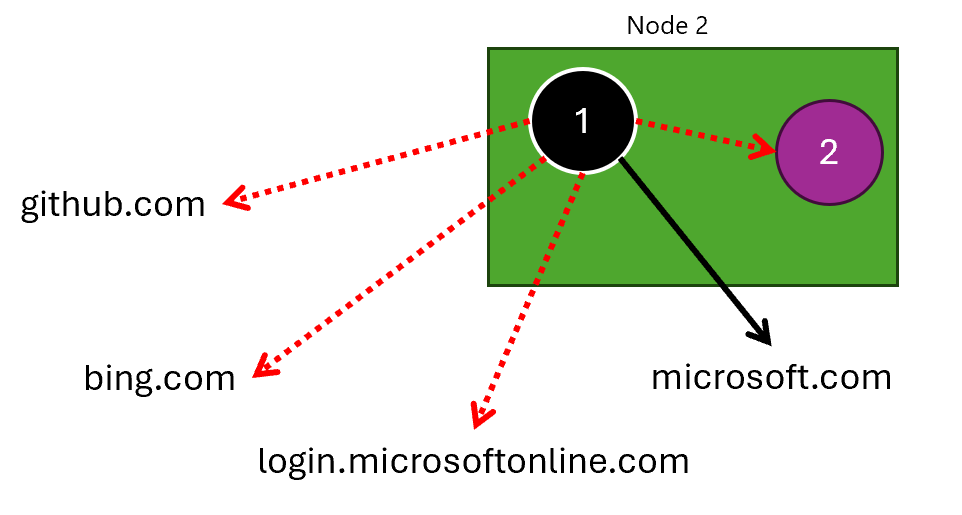
Here is the experiment configuration:
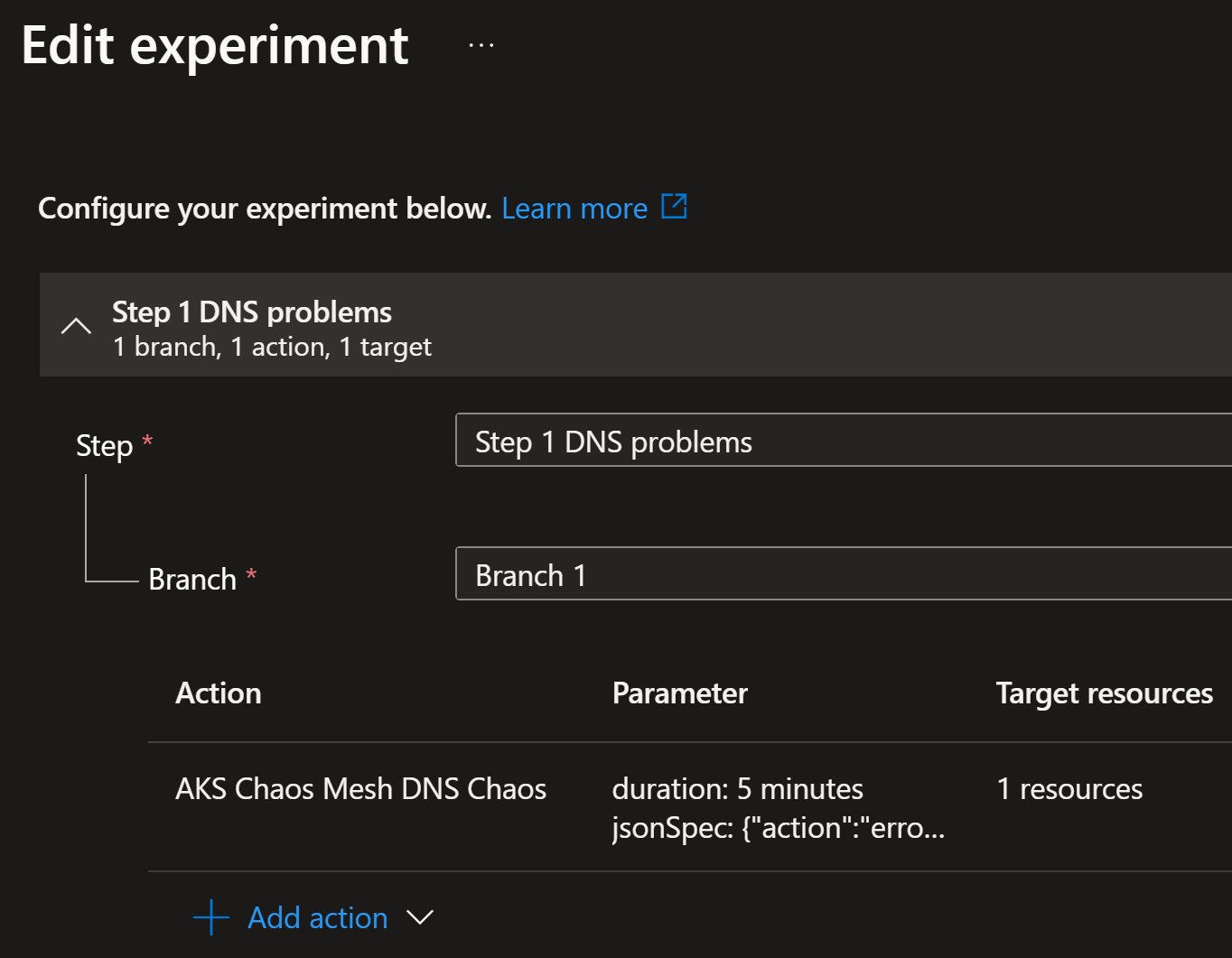
{
"action": "error",
"mode": "all",
"patterns": [
"bing.com",
"github.?om",
"login.microsoftonline.com",
"network-app-internal-svc.*"
],
"selector": {
"namespaces": [
"network-app",
"network-app2",
"update-app"
]
}
}
The above configuration is quite easy to understand. We are simulating DNS failures for the following domains:
bing.comgithub.com(or more specificallygithub.?omwith?as any character)login.microsoftonline.comnetwork-app-internal-svc
And we are targeting the following namespaces (other namespaces are not affected):
network-appnetwork-app2update-app
I’m again using my webapp-network-tester for demonstrating purposes. Read more about it here.
Webapp-network-tester workload is deployed to network-app namespace.
network-app-internal-svc is a service which is accessible within the cluster and
network-app-external-svc accessible from outside the cluster.
Now, we’re ready to show how the application works under normal circumstances.
If I send a payload IPLOOKUP bing.com to the application via Rest API, it should return the IP addresses of the domain bing.com:
$ curl -X POST --data "IPLOOKUP bing.com" "$network_app_external_svc_ip/api/commands"
-> Start: IPLOOKUP bing.com
IP: 13.107.21.200
IP: 204.79.197.200
IP: 2620:1ec:c11::200
<- End: IPLOOKUP bing.com 10.53ms
Similarly, it will reply with the list of IPs of those other domains as well.
I can also test the HTTP GET requests to the different addresses:
$ curl -X POST --data "HTTP GET http://network-app-internal-svc" "$network_app_external_svc_ip/api/commands"
-> Start: HTTP GET http://network-app-internal-svc
Hello there!
<- End: HTTP GET http://network-app-internal-svc 272.55ms
So, everything is working as expected.
Now, let’s start our experiment and see how the application behaves then:
After the experiment has started, we can see that configured DNS failures are happening:
$ curl -X POST --data "IPLOOKUP github.com" "$network_app_external_svc_ip/api/commands"
-> Start: IPLOOKUP github.com
System.Net.Sockets.SocketException (00000001, 11): Resource temporarily unavailable
at System.Net.Dns.GetHostEntryOrAddressesCore(String hostName, Boolean justAddresses, AddressFamily addressFamily, Nullable`1 startingTimestamp)
... <abbreviated>
<- End: IPLOOKUP github.com 417.04ms
Failure is also happening for the internal service DNS lookup:
$ curl -X POST --data "IPLOOKUP network-app-internal-svc" "$network_app_external_svc_ip/api/commands"
-> Start: IPLOOKUP network-app-internal-svc
System.Net.Sockets.SocketException (00000001, 11): Resource temporarily unavailable
at System.Net.Dns.GetHostEntryOrAddressesCore(String hostName, Boolean justAddresses, AddressFamily addressFamily, Nullable`1 startingTimestamp)
... <abbreviated>
<- End: IPLOOKUP network-app-internal-svc 2006.08ms
microsoft.com DNS lookup is still working fine during our experiment:
$ curl -X POST --data "IPLOOKUP microsoft.com" "$network_app_external_svc_ip/api/commands"
-> Start: IPLOOKUP microsoft.com
IP: 20.112.250.133
IP: 20.70.246.20
IP: 20.231.239.246
IP: 20.76.201.171
IP: 2603:1030:20e:3::23c
IP: 2603:1020:201:10::10f
IP: 2603:1030:c02:8::14
IP: 2603:1010:3:3::5b
IP: 2603:1030:b:3::152
<- End: IPLOOKUP microsoft.com 98.05ms
Similarly, HTTP GET requests are failing for the configured addresses:
$ curl -X POST --data "HTTP GET http://network-app-internal-svc" "$network_app_external_svc_ip/api/commands"
-> Start: HTTP GET http://network-app-internal-svc
System.Net.Http.HttpRequestException: Resource temporarily unavailable (network-app-internal-svc:80)
---> System.Net.Sockets.SocketException (11): Resource temporarily unavailable
... <abbreviated>
<- End: HTTP GET http://network-app-internal-svc 2008.51ms
$ curl -X POST --data "HTTP GET https://login.microsoftonline.com" "$network_app_external_svc_ip/api/commands"
-> Start: HTTP GET https://login.microsoftonline.com
System.Net.Http.HttpRequestException: Resource temporarily unavailable (login.microsoftonline.com:443)
---> System.Net.Sockets.SocketException (11): Resource temporarily unavailable
... <abbreviated>
<- End: HTTP GET https://login.microsoftonline.com 28.57ms
Other requests are still working fine:
$ curl -X POST --data "HTTP GET https://microsoft.com" "$network_app_external_svc_ip/api/commands"
-> Start: HTTP GET https://microsoft.com
<!DOCTYPE HTML>
<html lang="en-GB" dir="ltr">
... <abbreviated>
</body>
</html>
<- End: HTTP GET https://microsoft.com 2158.71ms
In the end, we can see that our application is still running and responding to our requests. So, it did not crash but obviously it could not resolve DNS to those configured addresses causing the above failures.
This is a good example of how you can use DNS Chaos to test out your application resiliency and many different network related scenarios.
Would your application survive if DNS is failing for some of the services e.g., database, storage, Redis, etc.?
How should it handle gracefully those kinds of failures?
Using Chaos Studio, you can easily test out your hypotheses with experiments.
Experiment 2: Simulate POD failure
In this experiment, we are going to simulate POD failures in our AKS cluster.
Here we have our cluster and apps (1) and (2) running in the cluster:
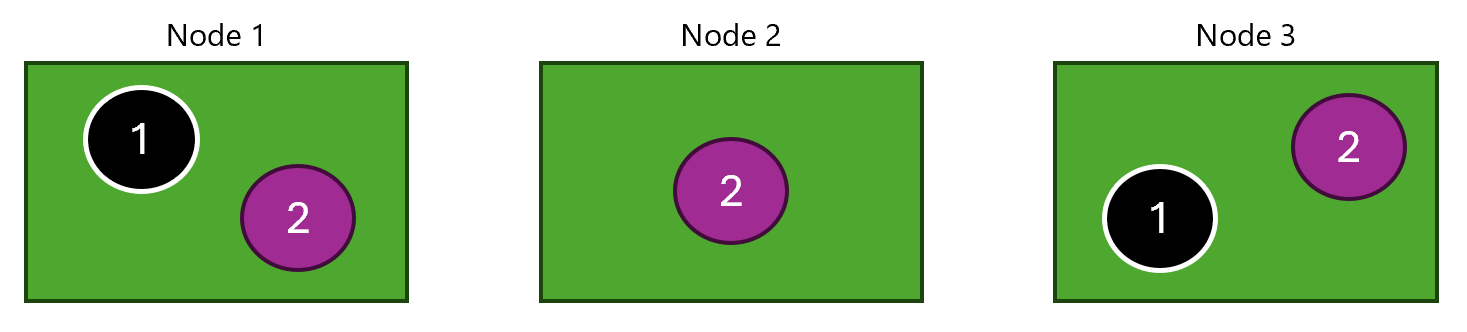
Apps have different counts of replicas, and they are spread across different nodes in the cluster.
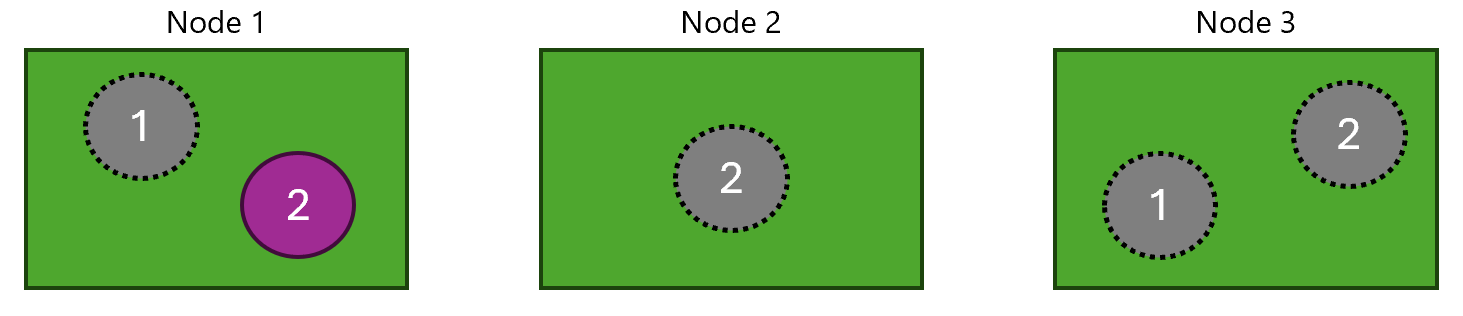
Now, we are going to simulate POD failures for the apps (1) and (2):
- For app
(1), we are going to simulate fixed number of POD failures of2 - For app
(2), we are going to simulate percentage of POD failures of66%
We expect that the (2) app will continue to run and be able to serve requests even if 66% of the PODs are failing
but (1) app will be completely down if 2 PODs are failing:
Here is the experiment configuration:
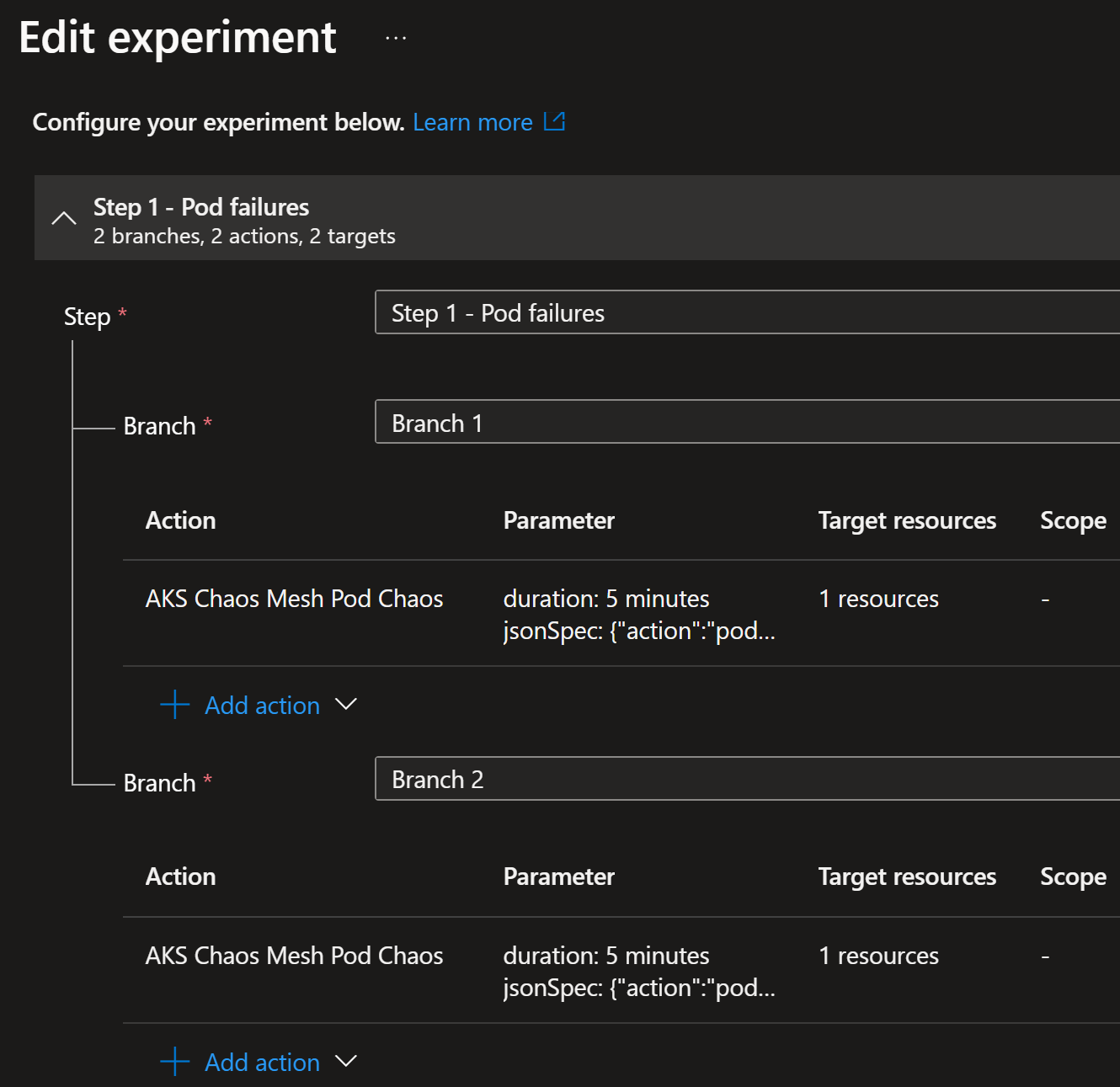
As you can see, there are now two branches in the experiment configuration for simulating two different configurations at the same time.
Fixed number of failures:
{
"action": "pod-failure",
"mode": "fixed",
"value": "2",
"duration": "300s",
"selector": {
"namespaces": [
"app1"
]
}
}
Percentage based number of failures:
{
"action": "pod-failure",
"mode": "fixed-percent",
"value": "66",
"duration": "300s",
"selector": {
"namespaces": [
"app2"
]
}
}
Now, let’s start our second experiment and see what happens:
After the experiment has started, we can see that (1) is completely down:
$ kubectl get pods -n app1
NAME READY STATUS RESTARTS AGE
app1-deployment-75787c7cdd-fzjxt 0/1 CrashLoopBackOff 3 (9s ago) 45h
app1-deployment-75787c7cdd-mxkmw 0/1 CrashLoopBackOff 3 (9s ago) 45h
$ curl $app1_svc_ip
curl: (28) Failed to connect to 4.158.40.219 port 80: Connection timed out
But (2) is still running and serving requests even if 66% of the PODs are failing:
$ kubectl get pods -n app2
NAME READY STATUS RESTARTS AGE
app2-deployment-858f68d4cd-jxlnn 1/1 Running 0 45h
app2-deployment-858f68d4cd-mzxmw 0/1 Running 5 (13s ago) 45h
app2-deployment-858f68d4cd-xxdn6 0/1 Running 5 (13s ago) 45h
$ curl -s $app2_svc_ip/api/update | jq .
{
"machineName": "app2-deployment-858f68d4cd-jxlnn",
"started": "2024-08-16T07:05:37.7032398Z",
"uptime": "00:00:13.4063413",
"appEnvironment": null,
"appEnvironmentSticky": null,
"content": "1.0.11\n"
}
This is good example how you can use POD Chaos to test out your application resiliency especially when you have microservices architecture and you have dependencies between different services. You can then use these to test out your implemented circuit breakers, retries, timeouts, etc. Here are a few links to the related resources:
- Retry pattern
- Circuit Breaker pattern
- Implement retries with exponential backoff
- Transient fault handling
Of course, you should start asking questions like these from yourself:
Would your application survive if some other service is not running at full capacity?
How many replicas you should have per service and how many of them can be down at the same time?
What if you’re under heavy load and some of the services are failing? Azure Load Testing is good companion for Chaos Studio for generating load to your services so that you can test the impact of the failures.
Experiment 3: Simulate availability zone failure
In this experiment, we are going to simulate availability zone failure in our 3 node AKS cluster:
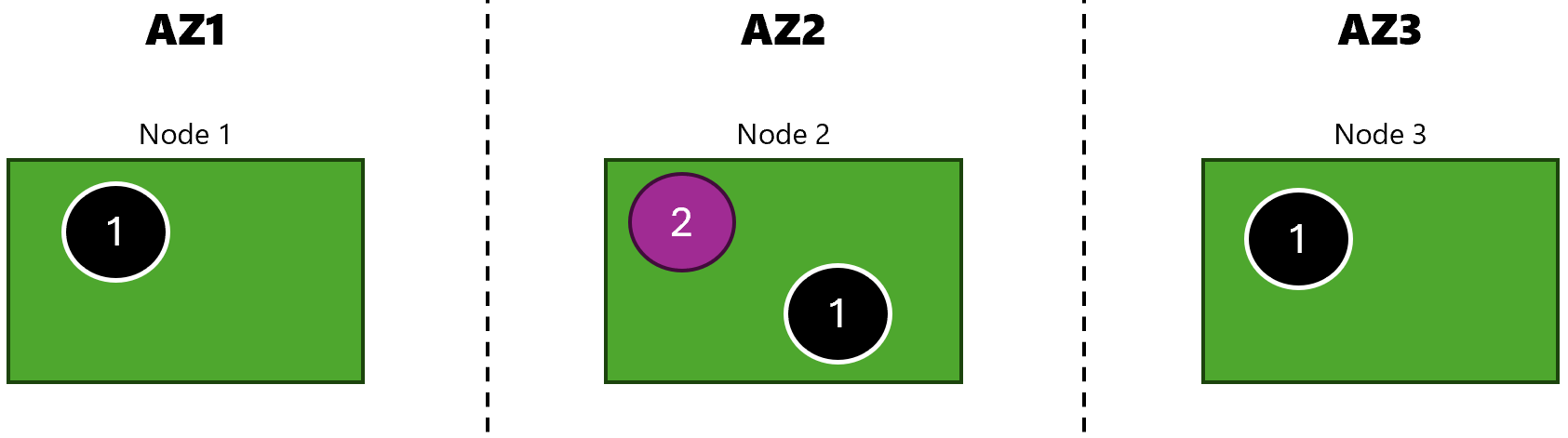
Here are our application deployments in the cluster:
I have helper list_pods function in my shell to list pods and their nodes and zones:
function list_pods()
{
declare -A node_map
while read node zone; do
node_map["$node"]="$zone"
done <<< $(kubectl get nodes --no-headers -o custom-columns=NAME:'{.metadata.name}',ZONE:'{metadata.labels.topology\.kubernetes\.io/zone}')
while read pod node; do
echo "Pod: $pod, Node: $node, Zone: ${node_map[$node]}"
done <<< $(kubectl get pod -n "$1" --no-headers -o custom-columns=NAME:'{.metadata.name}',NODE:'{.spec.nodeName}')
}
Here is example output of the function listing pods of app (1):
$ list_pods app1
Pod: app1-858f68d4cd-6hrvw, Node: aks-nodepool1-17464156-vmss000000, Zone: uksouth-1
Pod: app1-858f68d4cd-bhtjz, Node: aks-nodepool1-17464156-vmss000001, Zone: uksouth-2
Pod: app1-858f68d4cd-smxd4, Node: aks-nodepool1-17464156-vmss000002, Zone: uksouth-3
So I can see that they’re spread across different availability zones.
Similarly, here is listing of (2):
$ list_pods app2
Pod: app2-75787c7cdd-qbk8v, Node: aks-nodepool1-17464156-vmss000001, Zone: uksouth-2
Before starting the experiment, our cluster nodes are running as expected:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-17464156-vmss000000 Ready <none> 73m v1.30.3
aks-nodepool1-17464156-vmss000001 Ready <none> 5m46s v1.30.3
aks-nodepool1-17464156-vmss000002 Ready <none> 5m51s v1.30.3
Now, we are going to simulate availability zone 2 failure. Here is the experiment configuration:
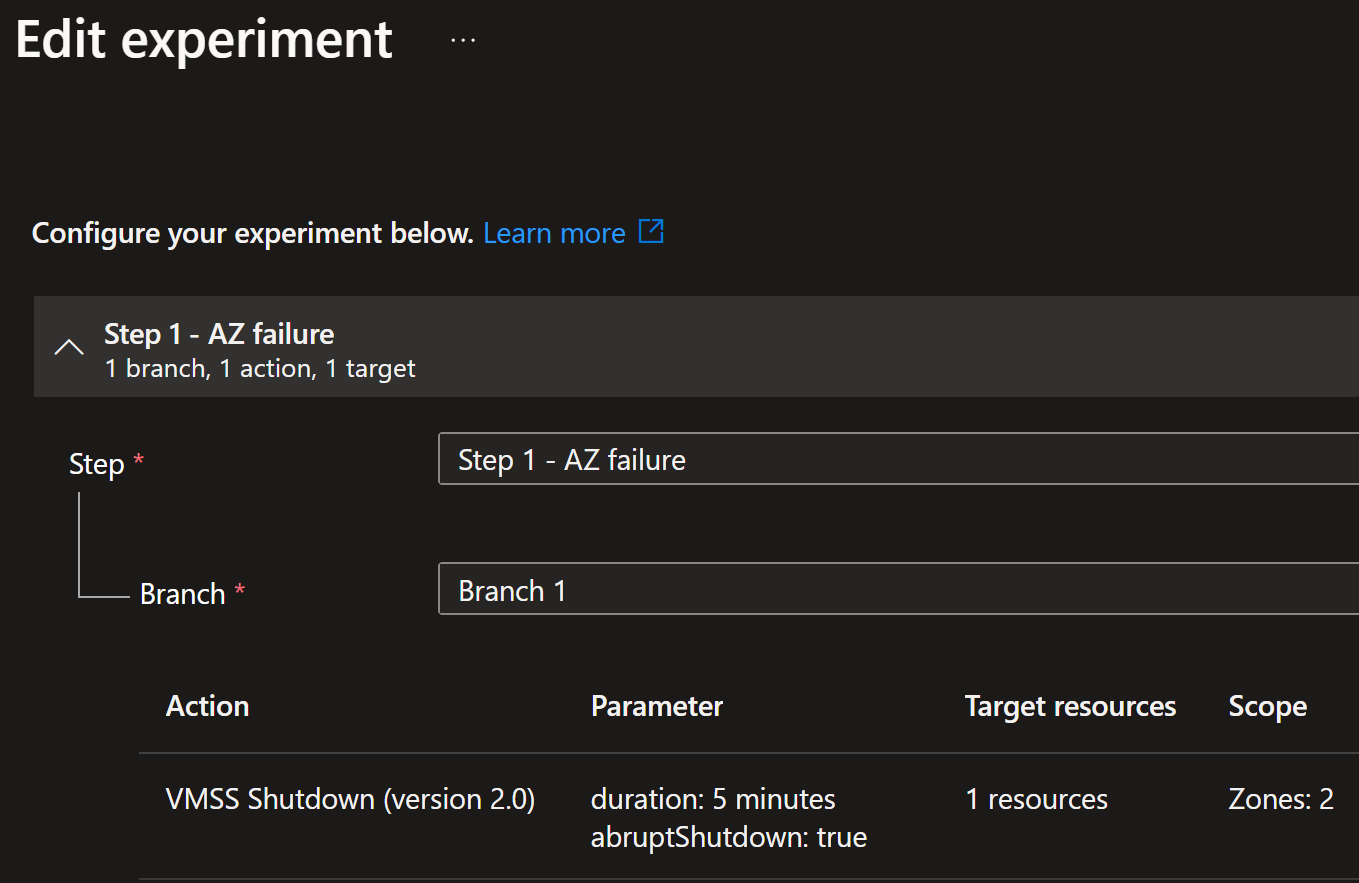
Now, let’s start our third experiment and see what happens:
After the experiment has started and availability zone 2 is impacted, many things start to happen:
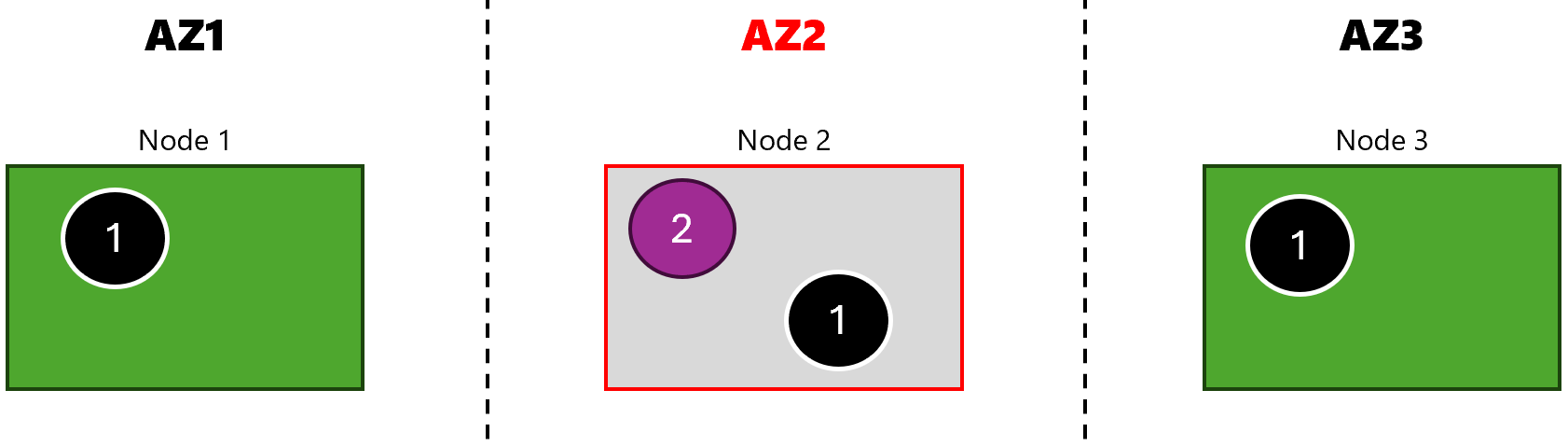
You might see that node is reported to be NotReady:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-17464156-vmss000000 Ready <none> 104m v1.30.3
aks-nodepool1-17464156-vmss000001 NotReady <none> 36m v1.30.3
aks-nodepool1-17464156-vmss000002 Ready <none> 36m v1.30.3
If we monitor our apps, we can see that they’re being rescheduled to other cluster nodes:
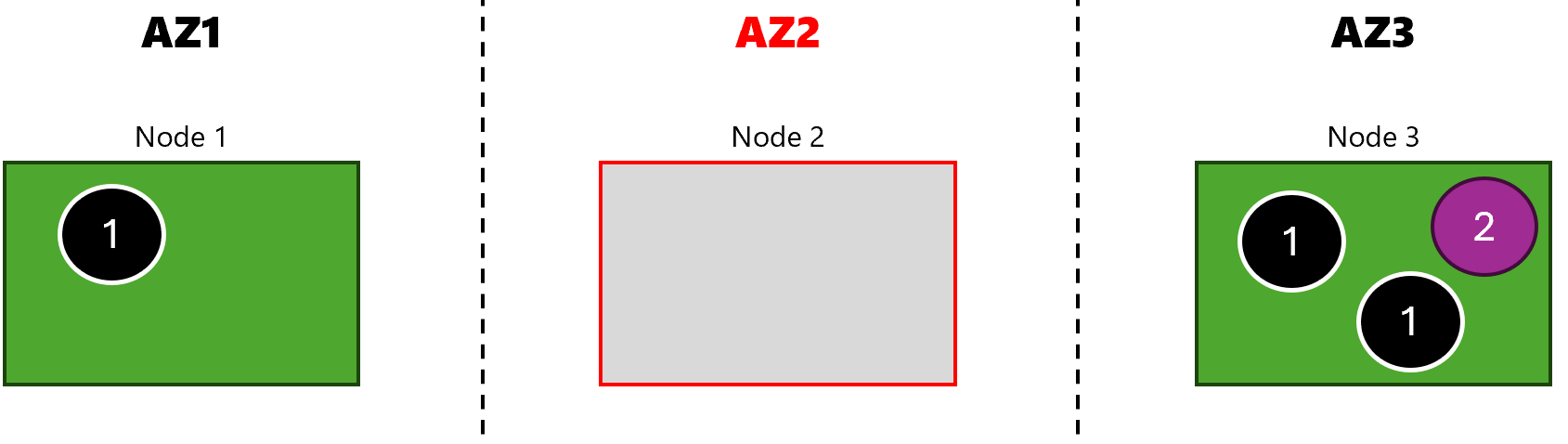
$ kubectl get pods -n app1 -w
NAME READY STATUS RESTARTS AGE
app1-858f68d4cd-bhtjz 1/1 Running 0 20m
app1-858f68d4cd-bhtjz 1/1 Terminating 0 20m
app1-858f68d4cd-bhblt 0/1 Pending 0 0s
app1-858f68d4cd-bhblt 0/1 ContainerCreating 0 0s
app1-858f68d4cd-bhblt 0/1 Running 0 1s
app1-858f68d4cd-bhtjz 1/1 Terminating 0 20m
app1-858f68d4cd-bhblt 1/1 Running 0 6s
$ list_pods app1
Pod: app1-858f68d4cd-6hrvw, Node: aks-nodepool1-17464156-vmss000000, Zone: uksouth-1
Pod: app1-858f68d4cd-bhblt, Node: aks-nodepool1-17464156-vmss000002, Zone: uksouth-3
Pod: app1-858f68d4cd-smxd4, Node: aks-nodepool1-17464156-vmss000002, Zone: uksouth-3
$ list_pods app2
Pod: app2-75787c7cdd-bhblt, Node: aks-nodepool1-17464156-vmss000002, Zone: uksouth-3
Here is the final state of the cluster after the experiment has completed:
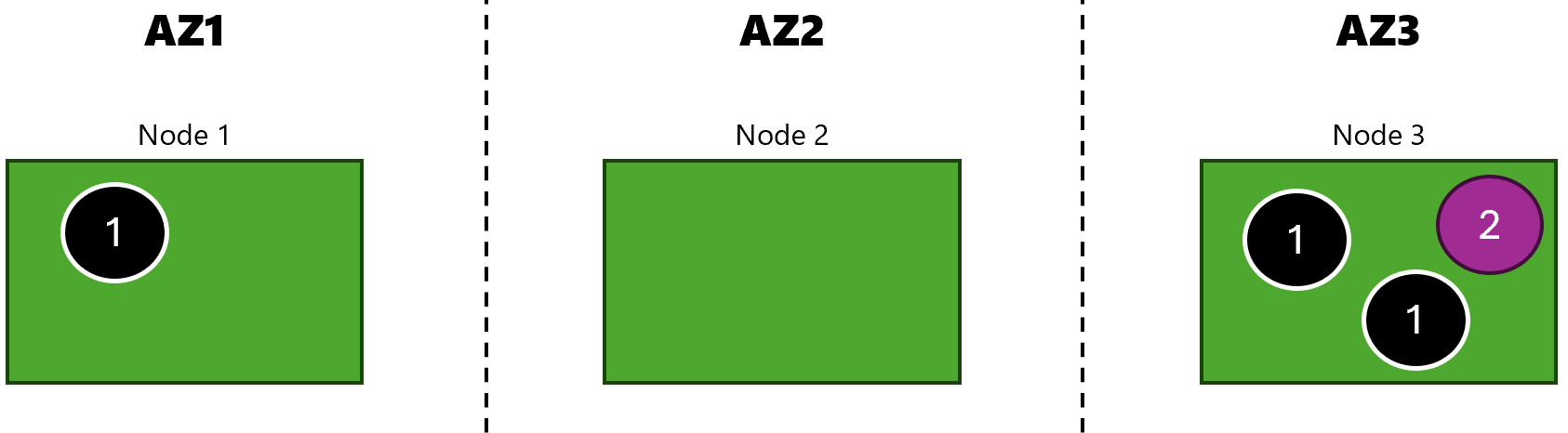
You can run the same experiment with larger clusters and see how it then behaves.
Starting point:
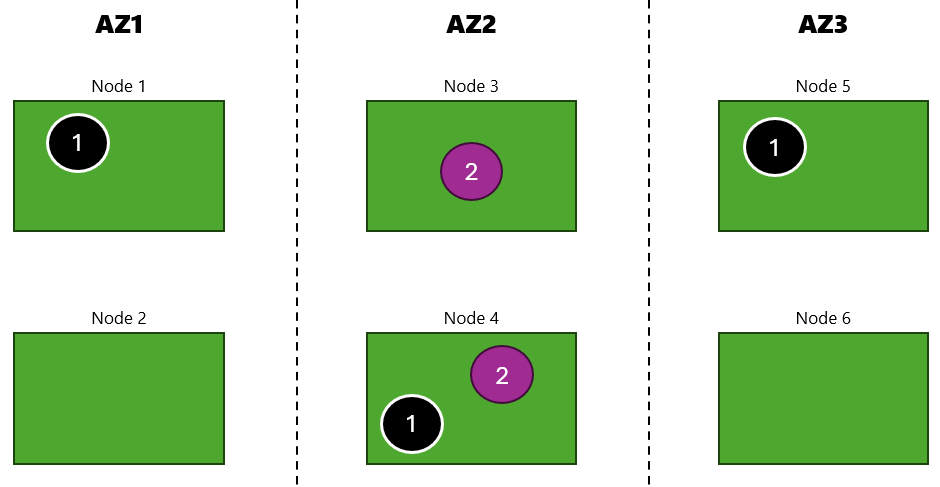
After the experiment has started:
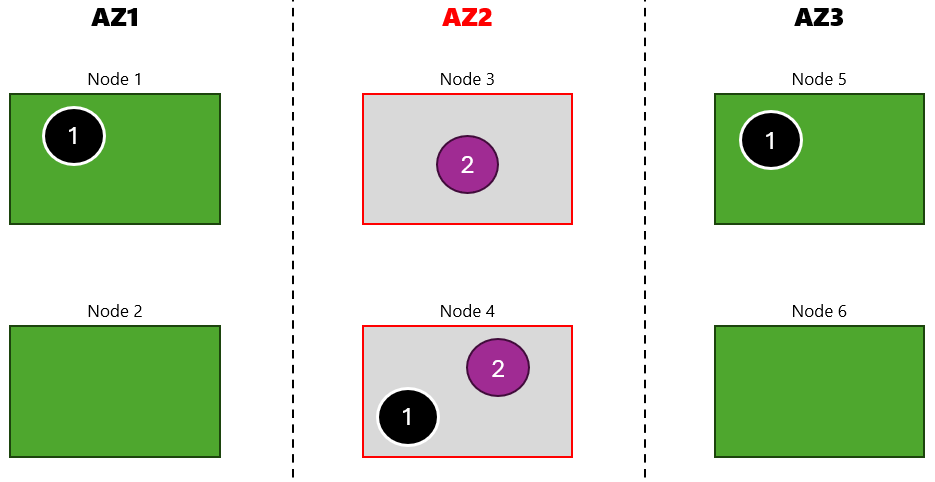
During the experiment:
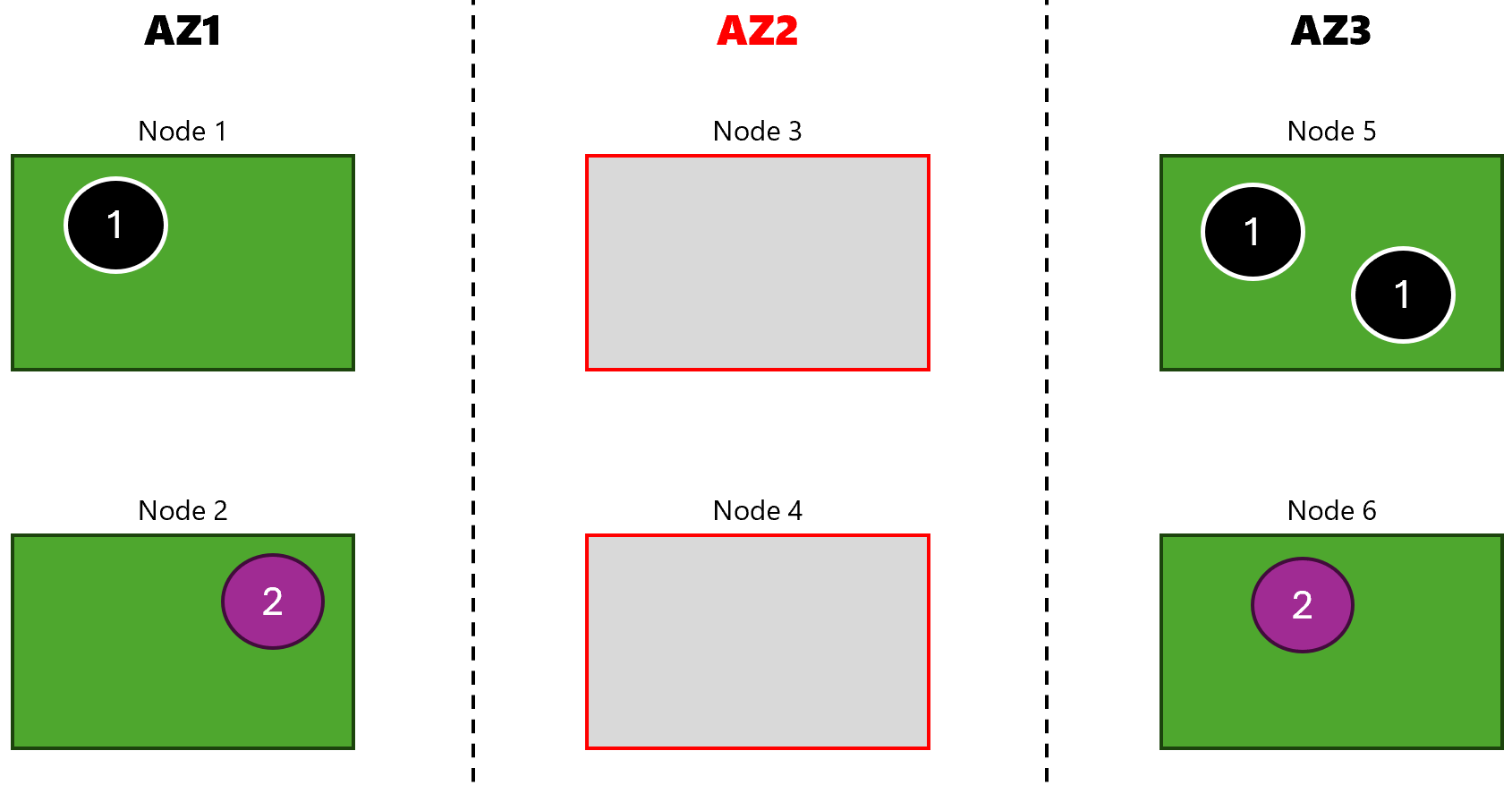
After the experiment has completed:
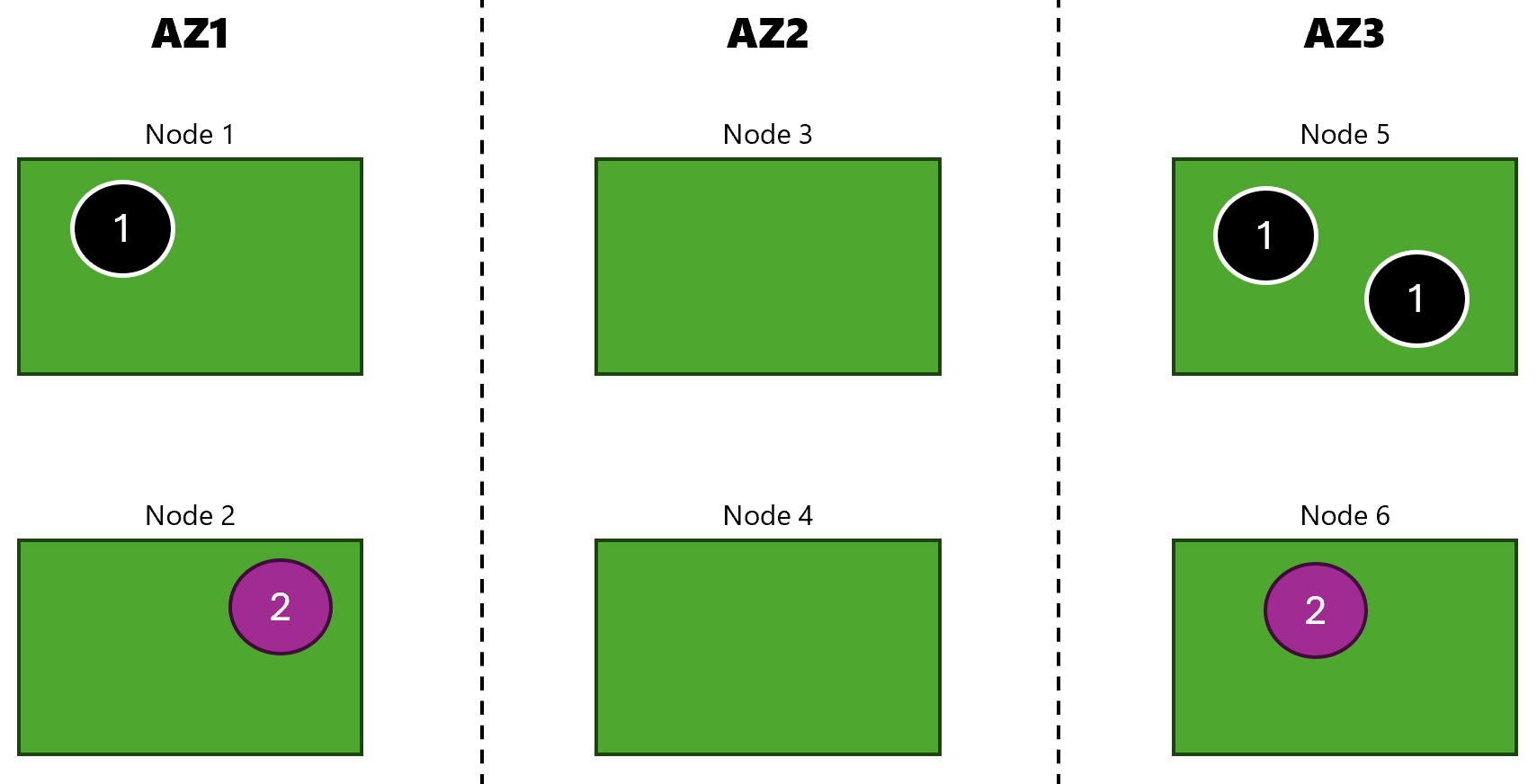
Availability Zone Chaos is an extremely powerful way to test out your AKS cluster resiliency.
There are tons of scenarios you can test out with it. You can test if you application is correctly deployed to across zones and nodes as you expected when you set various almost magical elements in your deployment configurations. Read more about Assigning Pods to Nodes.
Another important test scenario is persistent storage. When you put persistent storage to the picture, you might run into interesting issues. Especially, if you have deployed Locally redundant storage (LRS) disks into your cluster. Unfortunately, clusters with 1.28 and below don’t have storage classes with Zone-redundant storage (ZRS) support built-in. You have to create a storage class for that yourself. From Release 2024-04-28:
Effective starting with Kubernetes version 1.29, when you deploy Azure Kubernetes Service (AKS) clusters across multiple availability zones, AKS now utilizes zone-redundant storage (ZRS) to create managed disks within built-in storage classes.
This gives us many interesting scenarios to test out with Chaos Studio, including Azure Container Storage, but they do deserve their own post.
I blogged previously about Enhance your PowerPoint presentations with morph transitions and think it’s good way to illustrate these quite complex scenarios. Here is an example visualization of the above scenario:
Conclusion
In this post, we have seen how you can use Chaos Studio to test out your AKS cluster resiliency. We have seen how you can simulate DNS failures, POD failures, and availability zone failures.
Chaos Studio is a powerful tool for testing your hypotheses and making sure that your applications are resilient to failures.
This is a broad topic and I have only scratched the surface here. Expect to see more posts about these topics in the future.
You can find the above examples in my GitHub:
 JanneMattila/aks-workshop/26-chaos-studio.sh
JanneMattila/aks-workshop/26-chaos-studio.sh
I hope you find this useful!