AKS and Availability Zones with Locally Redundant Storage Disks
Posted on: October 7, 2024I blogged previously about Testing your AKS resiliency with Chaos Studio and this is a follow-up post on that topic. Please read the previous post to understand the context.
This time I have AKS deployed across two availability zones (AZs) and I need persistent storage for one of my apps:
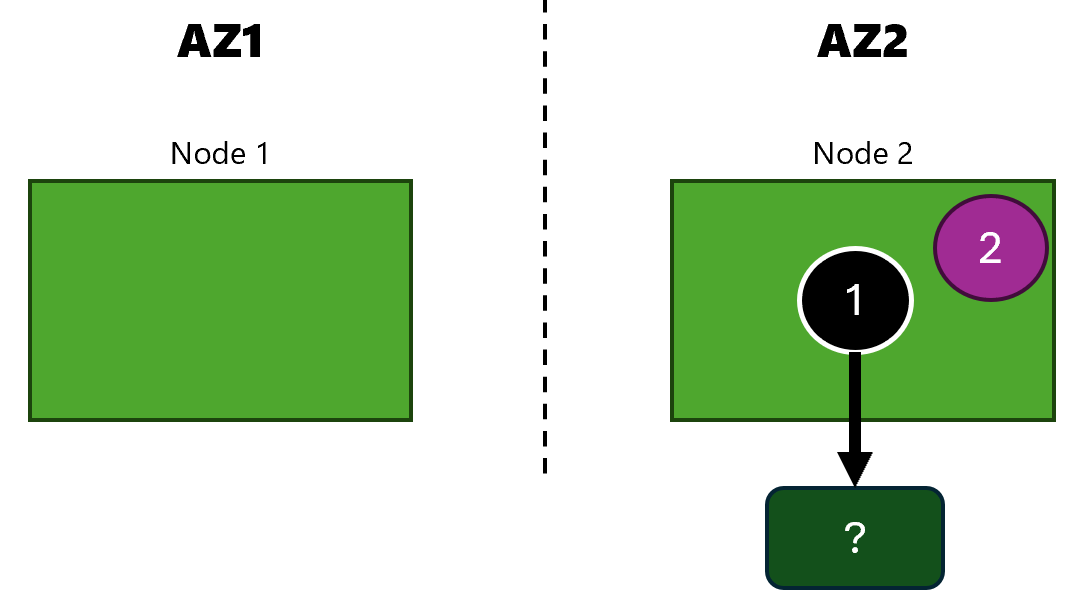
Notice that I have ? in the disk part of the architecture. That part will be filled next.
In Kubernetes, you can deploy persistent volumes either dynamically or statically.
Create and use a volume with Azure Disks in Azure Kubernetes Service (AKS)
Statically created volumes are pre-created by the cluster administrator and are available for consumption by the workloads in the cluster after they are created.
Dynamic volumes are created by the Kubernetes control plane when a workload requests a volume that does not exist. These will be created on-demand into the managed resource group (“MC_*”). Kubernetes uses storage classes when creating dynamic volumes.
As mentioned in the previous post (and AKS Release notes), storage classes in clusters with 1.28 and below don’t have Zone-redundant storage (ZRS) support built-in. This means that if you have not created a storage class with ZRS support, your disks will be created as Locally redundant storage (LRS).
From the above link:
Locally redundant storage (LRS) replicates your data three times within a single data center in the selected region
and
Zone-redundant storage (ZRS) synchronously replicates your Azure managed disk across three Azure availability zones in the region you select.
Unfortunately, the above unwanted scenario with LRS disks is not uncommon in the real world. In this post, I will demonstrate the impact of this on your applications and their availability. I use Azure Chaos Studio for simulating availability zone failure.
1.28.13 and older clusters
Let’s check our cluster and storage classes:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-35510824-vmss000000 Ready agent 12m v1.28.13
aks-nodepool1-35510824-vmss000001 Ready agent 12m v1.28.13
$ kubectl get storageclasses
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile file.csi.azure.com Delete Immediate true 13m
azurefile-csi file.csi.azure.com Delete Immediate true 13m
azurefile-csi-premium file.csi.azure.com Delete Immediate true 13m
azurefile-premium file.csi.azure.com Delete Immediate true 13m
default (default) disk.csi.azure.com Delete WaitForFirstConsumer true 13m
managed disk.csi.azure.com Delete WaitForFirstConsumer true 13m
managed-csi disk.csi.azure.com Delete WaitForFirstConsumer true 13m
managed-csi-premium disk.csi.azure.com Delete WaitForFirstConsumer true 13m
managed-premium disk.csi.azure.com Delete WaitForFirstConsumer true 13m
$ kubectl describe storageclass managed-csi-premium
Name: managed-csi-premium
IsDefaultClass: No
Annotations: <none>
Provisioner: disk.csi.azure.com
Parameters: skuname=Premium_LRS
AllowVolumeExpansion: True
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: WaitForFirstConsumer
Events: <none>
As you can see, managed-csi-premium storage class has Premium_LRS in the sku name indicating that it’s
Locally redundant storage (LRS).
The other storage classes for disk.csi.azure.com provisioner are also LRS.
I’ll deploy two apps, one with a disk and one without a disk. network-app is an app without disk (app 2 in the diagram) and
storage-app is the app with disk (app 1 in the diagram).
Here is the storage-app deployment:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: storage-app-deployment
namespace: storage-app
spec:
serviceName: storage-app-svc
podManagementPolicy: Parallel
replicas: 1
selector:
matchLabels:
app: storage-app
template:
metadata:
labels:
app: storage-app
spec:
nodeSelector:
kubernetes.io/os: linux
terminationGracePeriodSeconds: 10
containers:
- image: jannemattila/webapp-fs-tester:1.1.20
name: storage-app
ports:
- containerPort: 8080
name: http
protocol: TCP
volumeMounts:
- name: premiumdisk
mountPath: /mnt/premiumdisk
volumes:
- name: premiumdisk
persistentVolumeClaim:
claimName: premiumdisk-pvc
volumeClaimTemplates:
- metadata:
name: premiumdisk
spec:
accessModes:
- ReadWriteOnce
storageClassName: managed-csi-premium
resources:
requests:
storage: 4Gi
I’m using webapp-fs-tester for simulating disk operations. It’s available on Docker Hub:
Here is the dynamically created disk:
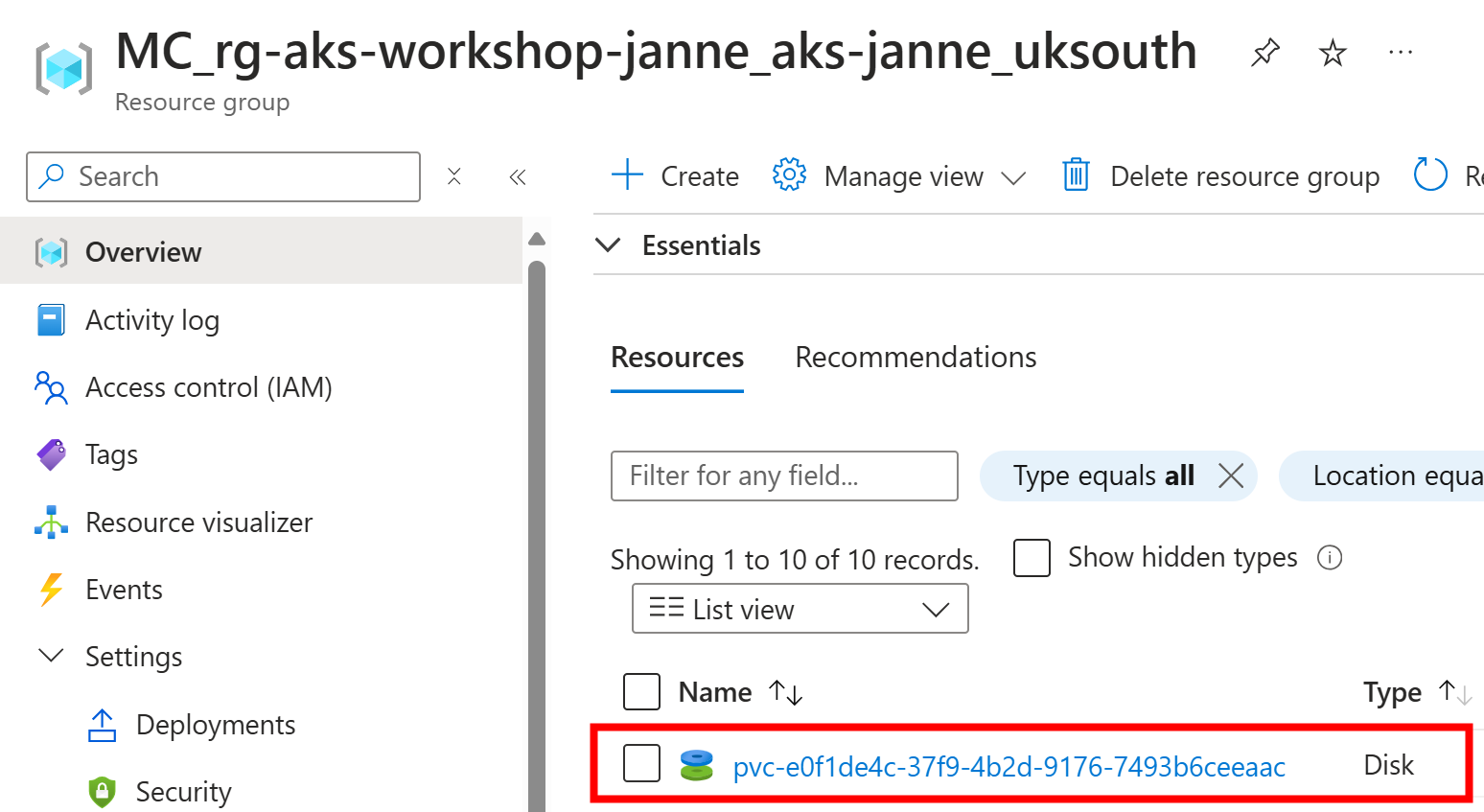
Basic information about the disk:

And below those properties is very important information about Availability zone:

That updates our architecture to this:
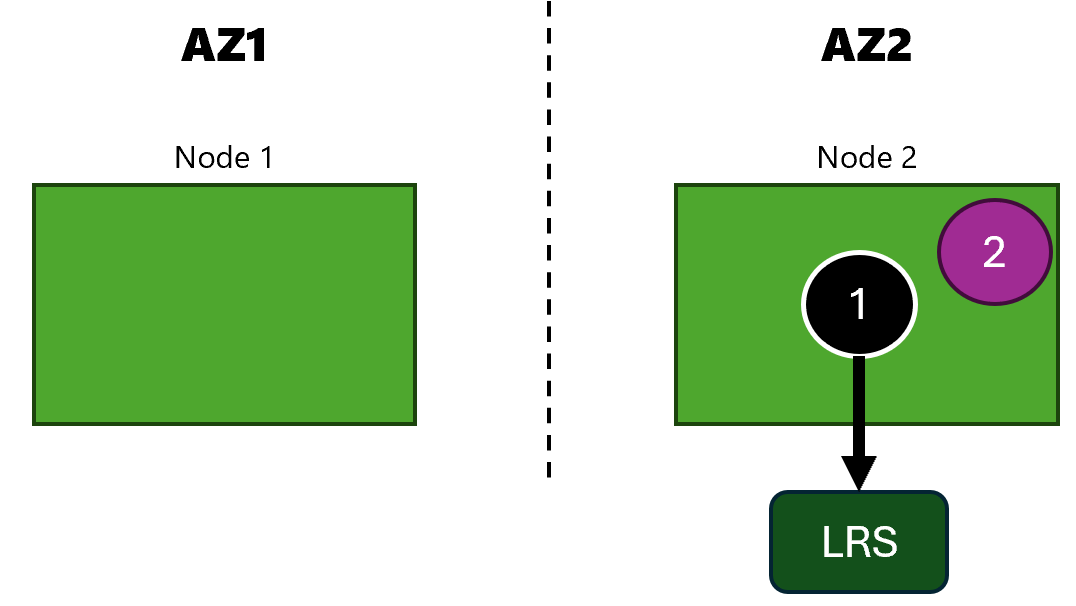
I have helper list_pods function in my shell to list pods and their nodes and zones:
$ list_pods storage-app
Pod: storage-app-deployment-0, Node: aks-nodepool1-35510824-vmss000001, Zone: uksouth-2
$ list_pods network-app
Pod: network-app-deployment-66ffb56b96-x4m9n, Node: aks-nodepool1-35510824-vmss000001, Zone: uksouth-2
So, both apps are running in the availability zone 2.
Let’s generate some files to the disk and list them using the rest API of the storage-app:
$ curl -s -X POST \
--data '{"path": "/mnt/premiumdisk","folders": 2,"subFolders": 3,"filesPerFolder": 5,"fileSize": 1024}' \
-H "Content-Type: application/json" \
"http://$storage_app_ip/api/generate" | jq .
{
"server": "storage-app-deployment-0",
"path": "/mnt/premiumdisk",
"filesCreated": 40,
"milliseconds": 7.972
}
$ curl -s -X POST \
--data '{"path": "/mnt/premiumdisk","filter": "*.*","recursive": true}' \
-H "Content-Type: application/json" \
"http://$storage_app_ip/api/files" | jq .
{
"server": "storage-app-deployment-0",
"files": [
"/mnt/premiumdisk/1/1/1/2.txt",
"...abbreviated...",
"/mnt/premiumdisk/2/2/2/4.txt"
],
"milliseconds": 0.54
}
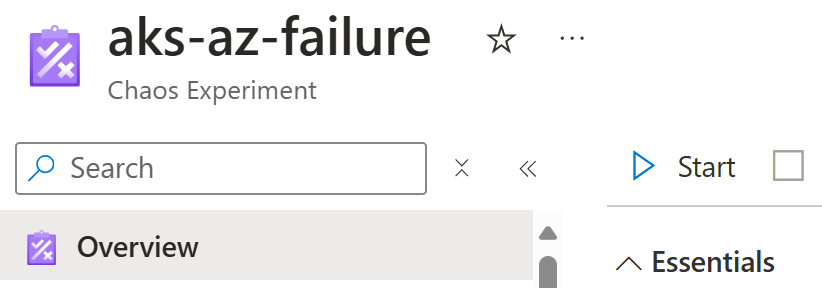
Now we’re ready to simulate an availability zone failure using Azure Chaos Studio:
When the chaos experiment is running, our node in zone 2 becomes unavailable:
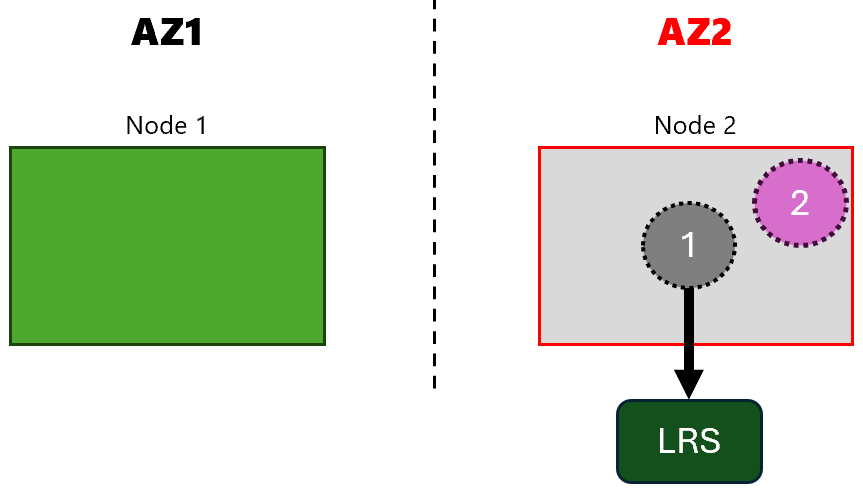
Kubernetes now tries to move the pods to the available nodes in our cluster. For the network-app (app without disk), this is easy:
$ kubectl get pods -n network-app -w
NAME READY STATUS RESTARTS AGE
network-app-deployment-66ffb56b96-x4m9n 1/1 Running 0 29m
network-app-deployment-66ffb56b96-x4m9n 1/1 Running 0 37m
network-app-deployment-66ffb56b96-x4m9n 1/1 Running 0 37m
network-app-deployment-66ffb56b96-x4m9n 1/1 Terminating 0 37m
network-app-deployment-66ffb56b96-ncn65 0/1 Pending 0 0s
network-app-deployment-66ffb56b96-ncn65 0/1 Pending 0 0s
network-app-deployment-66ffb56b96-ncn65 0/1 ContainerCreating 0 0s
network-app-deployment-66ffb56b96-ncn65 1/1 Running 0 6s
network-app-deployment-66ffb56b96-x4m9n 1/1 Terminating 0 37m
network-app-deployment-66ffb56b96-x4m9n 1/1 Terminating 0 37m
network-app-deployment-66ffb56b96-x4m9n 1/1 Terminating 0 37m
But for the storage-app (app with disk), situation is bad and we’re experiencing down time as long as the node is unavailable:
$ kubectl get pod -n storage-app -w
NAME READY STATUS RESTARTS AGE
storage-app-deployment-0 1/1 Running 0 19m
storage-app-deployment-0 1/1 Running 0 27m
storage-app-deployment-0 1/1 Running 0 27m
storage-app-deployment-0 1/1 Terminating 0 27m
storage-app-deployment-0 1/1 Terminating 0 27m
storage-app-deployment-0 1/1 Terminating 0 27m
storage-app-deployment-0 1/1 Terminating 0 27m
storage-app-deployment-0 0/1 Pending 0 0s
storage-app-deployment-0 0/1 Pending 0 0s
storage-app-deployment-0 0/1 Pending 0 4m45s
storage-app-deployment-0 0/1 ContainerCreating 0 4m46s
storage-app-deployment-0 1/1 Running 0 4m56s
The app was in Pending state for almost 5 minutes (=duration of our chaos experiment):
If we study the events of the pod, we can see additional information:
$ kubectl describe pod -n storage-app
...abbreviated...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 30s default-scheduler 0/2 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/unreachable: }, 1 node(s) had volume node affinity conflict. preemption: 0/2 nodes are available: 2 Preemption is not helpful for scheduling..
Normal NotTriggerScaleUp 26s cluster-autoscaler pod didn't trigger scale-up: 1 node(s) had volume node affinity conflict
Message from the event is:
0/2 nodes are available:
1 node(s) had untolerated taint {node.kubernetes.io/unreachable: },
1 node(s) had volume node affinity conflict.
preemption: 0/2 nodes are available: 2 Preemption is not helpful for scheduling.
So, the storage-app pod is not scheduled to the zone 1 node because of the volume node affinity conflict.
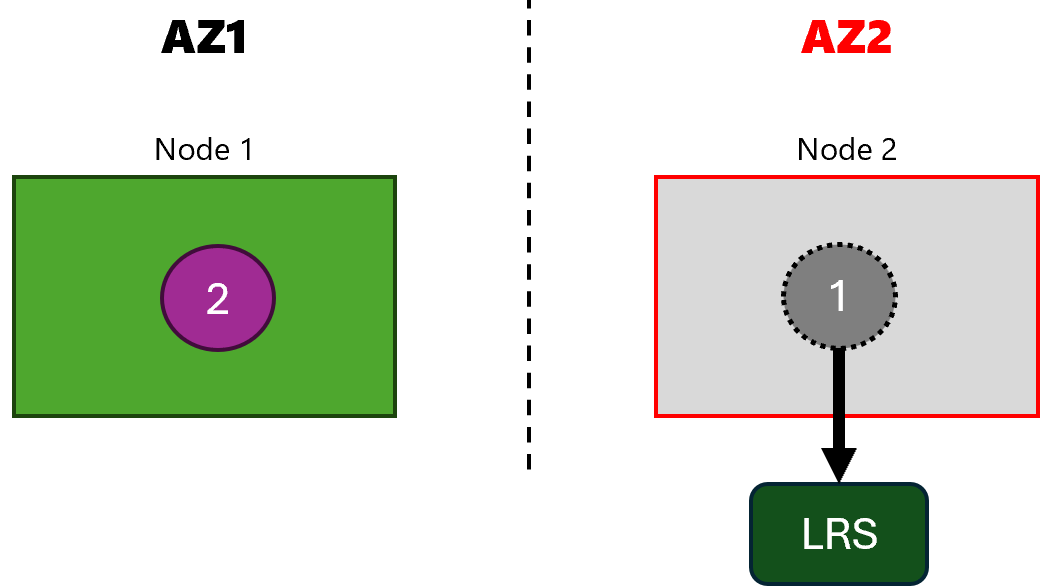
After our chaos experiment is over and the node in zone 2 is available again, the storage-app pod is scheduled back to that node:
More information: Disk cannot be attached to the VM because it is not in the same zone as the VM.
1.29 and newer clusters
So, let’s compare the above test with newly deployed cluster and storage classes:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-17464156-vmss000009 Ready <none> 12m v1.30.3
aks-nodepool1-17464156-vmss00000a Ready <none> 100s v1.30.3
$ kubectl get storageclasses
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile file.csi.azure.com Delete Immediate true 38d
azurefile-csi file.csi.azure.com Delete Immediate true 38d
azurefile-csi-premium file.csi.azure.com Delete Immediate true 38d
azurefile-premium file.csi.azure.com Delete Immediate true 38d
default (default) disk.csi.azure.com Delete WaitForFirstConsumer true 38d
managed disk.csi.azure.com Delete WaitForFirstConsumer true 38d
managed-csi disk.csi.azure.com Delete WaitForFirstConsumer true 38d
managed-csi-premium disk.csi.azure.com Delete WaitForFirstConsumer true 38d
managed-premium disk.csi.azure.com Delete WaitForFirstConsumer true 38d
$ kubectl describe storageclass managed-csi-premium
Name: managed-csi-premium
IsDefaultClass: No
Annotations: <none>
Provisioner: disk.csi.azure.com
Parameters: skuname=Premium_ZRS
AllowVolumeExpansion: True
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: WaitForFirstConsumer
Events: <none>
As you can see, the newer cluster has built-in storage classes with “ZRS” support.
Let’s deploy the same apps to this cluster. I’m using the same deployment yaml files as in the previous test.
Here is the created disk:

And now the important information about Availability zone is different:

Our disk is now created as “Zone-redundant storage (ZRS)” and we can update our architecture to this:
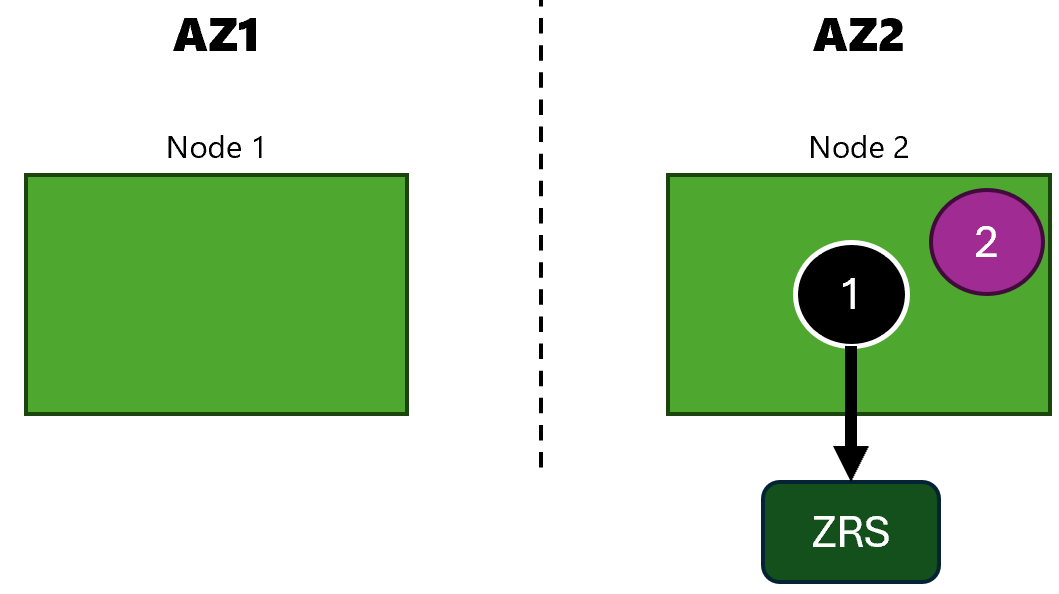
Apps are running in availability zone 2 as in the previous test:
$ list_pods storage-app
Pod: storage-app-deployment-0, Node: aks-nodepool1-17464156-vmss00000a, Zone: uksouth-2
$ list_pods network-app
Pod: network-app-deployment-76c7c7cdc5-4wzs2, Node: aks-nodepool1-17464156-vmss00000a, Zone: uksouth-2
Again, I’ll generate some files to the disk to see that everything is working as expected:
$ curl -s -X POST \
--data '{"path": "/mnt/premiumdisk","folders": 2,"subFolders": 3,"filesPerFolder": 5,"fileSize": 1024}' \
-H "Content-Type: application/json" \
"http://$storage_app_ip/api/generate" | jq .
{
"server": "storage-app-deployment-0",
"path": "/mnt/premiumdisk",
"filesCreated": 40,
"milliseconds": 7.3026
}
$ curl -s -X POST \
--data '{"path": "/mnt/premiumdisk","filter": "*.*","recursive": true}' \
-H "Content-Type: application/json" \
"http://$storage_app_ip/api/files" | jq .
{
"server": "storage-app-deployment-0",
"files": [
"/mnt/premiumdisk/1/1/1/2.txt",
"...abbreviated...",
"/mnt/premiumdisk/2/2/2/4.txt"
],
"milliseconds": 0.7606
}
Let’s repeat our experiment with this cluster:
Next step is the same as earlier, the node in zone 2 becomes unavailable:
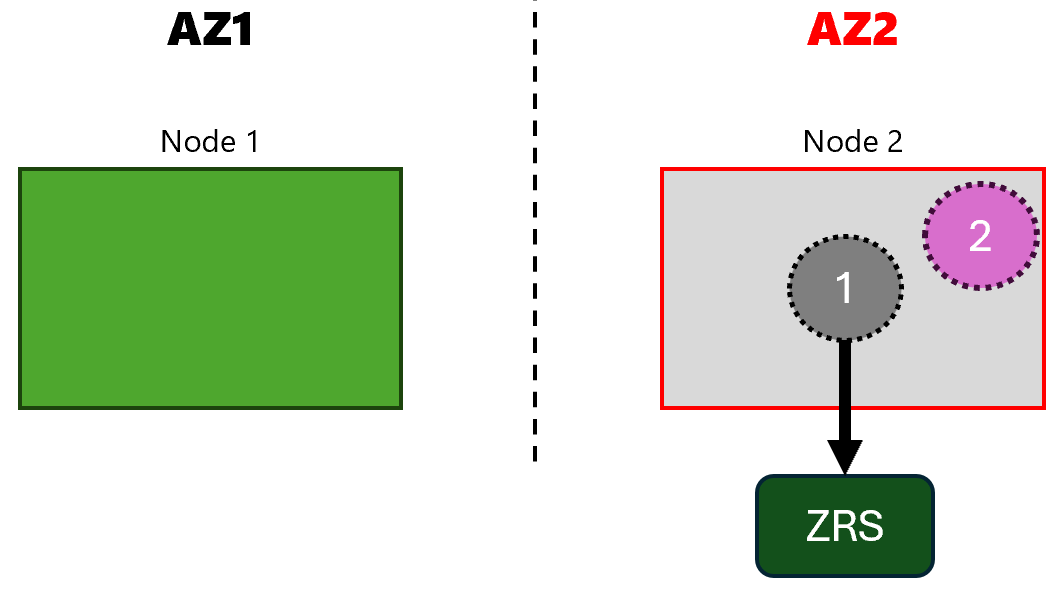
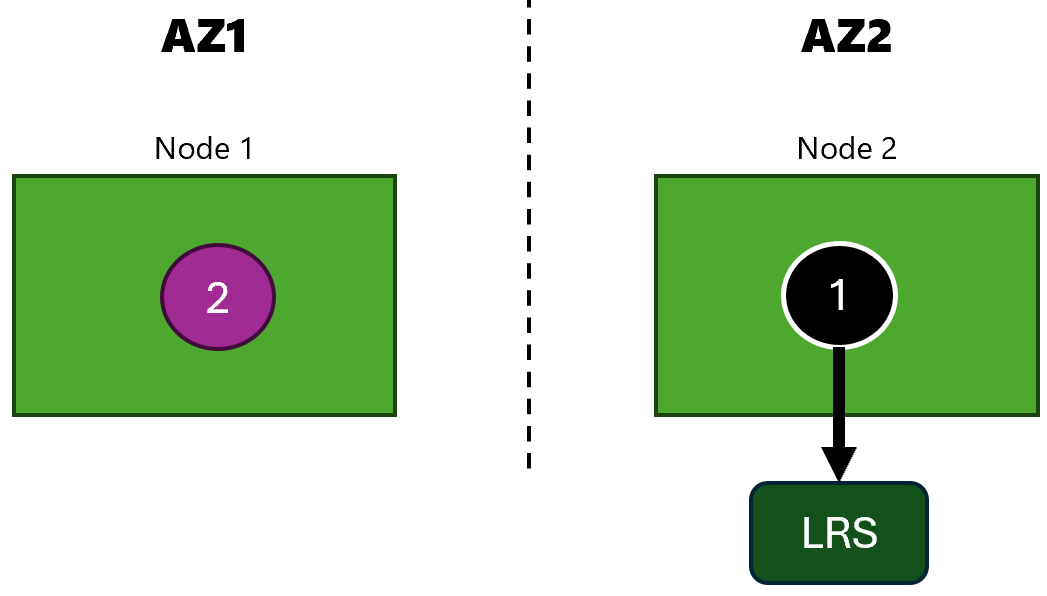
However, this time the storage-app pod is moved to the zone 1 node without any issues:
$ kubectl get pod -n storage-app -w
NAME READY STATUS RESTARTS AGE
storage-app-deployment-0 1/1 Running 0 18m
storage-app-deployment-0 1/1 Running 0 18m
storage-app-deployment-0 1/1 Running 0 18m
storage-app-deployment-0 1/1 Terminating 0 18m
storage-app-deployment-0 1/1 Terminating 0 18m
storage-app-deployment-0 1/1 Terminating 0 18m
storage-app-deployment-0 1/1 Terminating 0 18m
storage-app-deployment-0 0/1 Pending 0 0s
storage-app-deployment-0 0/1 Pending 0 0s
storage-app-deployment-0 0/1 ContainerCreating 0 0s
storage-app-deployment-0 1/1 Running 0 22s
Obviously, network-app (application without disk) was moved to zone 1 again without any problems.
If we now list_pods again, we can see that the storage-app pod is now running in the zone 1 node:
$ list_pods storage-app
Pod: storage-app-deployment-0, Node: aks-nodepool1-17464156-vmss000009, Zone: uksouth-1
$ list_pods network-app
Pod: network-app-deployment-8656fdf5df-t6m9w, Node: aks-nodepool1-17464156-vmss000009, Zone: uksouth-1
This updates our architecture to this during the experiment:
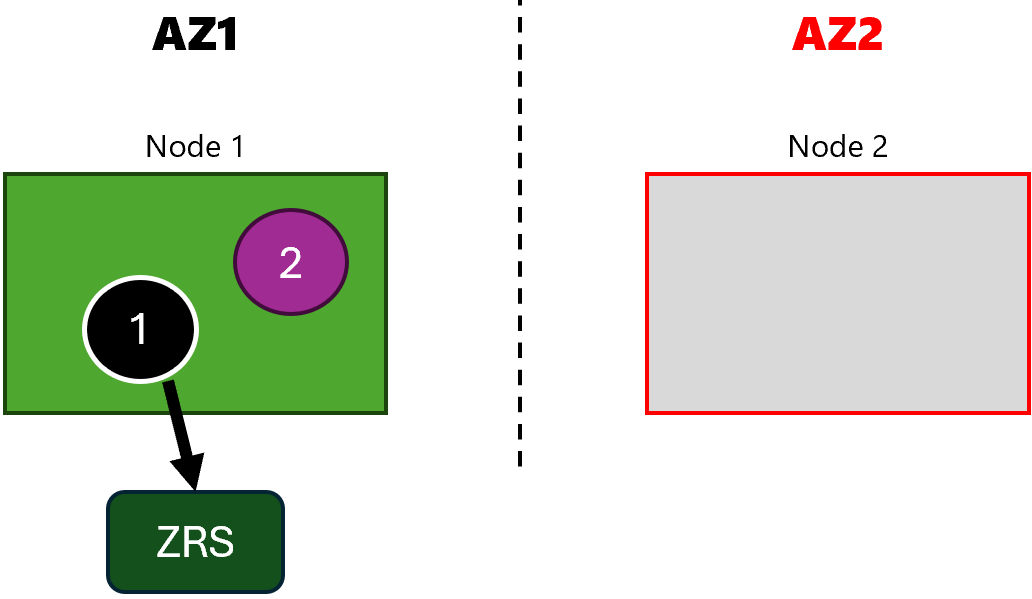
After the chaos experiment is over, no big surprises, since everything is already working and only the node in zone 2 becomes available again:
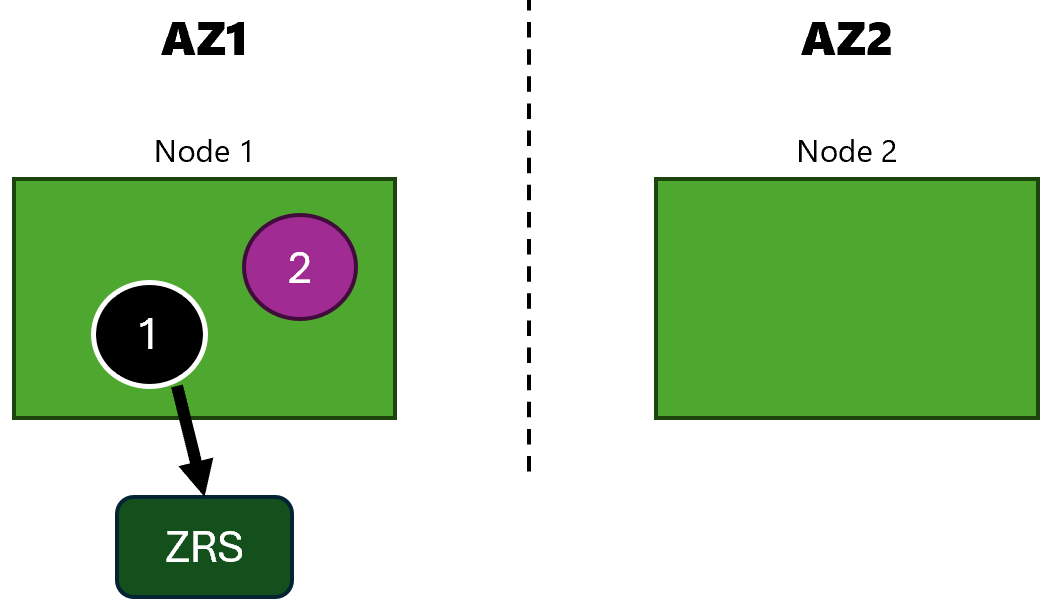
But wait, I’ve upgraded my cluster to 1.30. Am I safe now?
I’ve upgraded my first cluster to 1.30.3, so let’s see if the storage classes have been updated:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-35510824-vmss000000 Ready <none> 8m7s v1.30.3
aks-nodepool1-35510824-vmss000001 Ready <none> 4m59s v1.30.3
$ kubectl get storageclasses
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
azurefile file.csi.azure.com Delete Immediate true 101m
azurefile-csi file.csi.azure.com Delete Immediate true 101m
azurefile-csi-premium file.csi.azure.com Delete Immediate true 101m
azurefile-premium file.csi.azure.com Delete Immediate true 101m
default (default) disk.csi.azure.com Delete WaitForFirstConsumer true 101m
managed disk.csi.azure.com Delete WaitForFirstConsumer true 101m
managed-csi disk.csi.azure.com Delete WaitForFirstConsumer true 101m
managed-csi-premium disk.csi.azure.com Delete WaitForFirstConsumer true 101m
managed-premium disk.csi.azure.com Delete WaitForFirstConsumer true 101m
$ kubectl describe storageclass managed-csi-premium
Name: managed-csi-premium
IsDefaultClass: No
Annotations: <none>
Provisioner: disk.csi.azure.com
Parameters: skuname=Premium_LRS
AllowVolumeExpansion: True
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: WaitForFirstConsumer
Events: <none>
As you can see, the storage classes are still the same as before the upgrade. This means that to use ZRS disks, you need to create new storage classes with ZRS support and update your applications to use them.
But wait, I want to migrate my app to use ZRS disks
Okay this part gets easily complicated, but let’s try to touch this topic as well. First, you should understand the scope and complexity of migration.
Have you deployed 10s or 100s of apps with disks in your AKS cluster?
Are you using deployments or stateful sets?
Are you using GitOps or do you deploy with kubectl apply -f?
Did you install Helm charts from Artifact Hub e.g., Redis and it created those disks for you?
Is it an option to delete that data and start from scratch e.g., cache data? Or deploy a new solution side-by-side and migrate other apps to use it?
How do you do backups currently? Surely you have strategy for your backups? Can you use that in this migration? No matter how you approach this migration, you should have a backup implementation. This itself is a big topic and I’ll cover that in a future post. Plan for failure and accidental disk deletion.
Most likely, you must plan for a maintenance window for the migration. If that is not an option, then you have to plan your steps very carefully.
Does your application already synchronize the data between each of its instances in the application layer? If that is the case, and you have your instances running in different availability zones, then does it matter if the disk is LRS or ZRS? Especially if you have configured the deployment to span across multiple availability zones.
If we keep the scope just in the storage-app in this post, then
we can use
Init Containers
for handling the data migration.
Let’s see how to do this in practice. Let’s get back to the first cluster with 1.28.13 version:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
aks-nodepool1-15003373-vmss000000 Ready agent 2m49s v1.28.13
$ kubectl describe storageclass managed-csi-premium
Name: managed-csi-premium
IsDefaultClass: No
Annotations: <none>
Provisioner: disk.csi.azure.com
Parameters: skuname=Premium_LRS
AllowVolumeExpansion: True
MountOptions: <none>
ReclaimPolicy: Delete
VolumeBindingMode: WaitForFirstConsumer
Events: <none>
I have my storage_app deployed and I’ll generate data to the disk:
$ curl -s -X POST \
--data '{"path": "/mnt/premiumdisk","folders": 5,"subFolders": 5,"filesPerFolder": 5,"fileSize": 100000}' \
-H "Content-Type: application/json" \
"http://$storage_app_ip/api/generate" | jq .
{
"server": "storage-app-deployment-0",
"path": "/mnt/premiumdisk",
"filesCreated": 15625,
"milliseconds": 9155.1445
}
We can exec into the pod and see the used disk space:
$ kubectl exec --stdin --tty storage-app-deployment-0 -n storage-app -- /bin/sh
/app # df -h /mnt/premiumdisk
Filesystem Size Used Available Use% Mounted on
/dev/sdc 3.9G 1.5G 2.3G 39% /mnt/premiumdisk
/app # find /mnt/premiumdisk -type f -follow | wc -l
15625
So, we have no 15000+ files on the disk and they’re using 1.5GB disk space.
Before we start the migration, we must create a new storage class with ZRS support:
$ cat managed-csi-premium-zrs.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-csi-premium-zrs
provisioner: disk.csi.azure.com
parameters:
skuName: Premium_ZRS
reclaimPolicy: Delete
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
$ kubectl apply -f managed-csi-premium-zrs.yaml
Next, we have to update our storage-app to use two disks at the same time.
One disk is the old LRS disk and the other is the new ZRS disk created using the new storage class.
In order to migrate the data from the old disk to the new disk,
we’re creating an init container migration that copies the data from the old disk to the new disk.
Old disk: /mnt/premiumdisk (LRS)
New disk: /mnt/premiumdisk-zrs (ZRS)
Here is an example script for migrating the data:
if [ -e /mnt/premiumdisk/migrated ]
then
echo "$(date) - Data already migrated previously!"
else
echo "$(date) - Migrate data from LRS to ZRS..."
cp -R /mnt/premiumdisk/* /mnt/premiumdisk-zrs
echo "$(date) - Data migrate completed!"
touch /mnt/premiumdisk/migrated
fi
The logic of the script is simple:
- If the file
/mnt/premiumdisk/migratedexists, then the data has already been migrated previously. - If the file does not exist, then the data is copied from the old disk to the new disk.
Here is the updated storage-app deployment with the init container:
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: storage-app-deployment
namespace: storage-app
spec:
serviceName: storage-app-svc
podManagementPolicy: Parallel
replicas: 1
selector:
matchLabels:
app: storage-app
template:
metadata:
labels:
app: storage-app
spec:
nodeSelector:
kubernetes.io/os: linux
terminationGracePeriodSeconds: 10
initContainers:
- name: migration
image: jannemattila/webapp-fs-tester:1.1.20
volumeMounts:
- name: premiumdisk
mountPath: /mnt/premiumdisk
- name: premiumdisk-zrs
mountPath: /mnt/premiumdisk-zrs
command: ["/bin/sh", "-c"]
args:
- |
if [ -e /mnt/premiumdisk/migrated ]
then
echo "$(date) - Data already migrated previously!"
else
echo "$(date) - Migrate data from LRS to ZRS..."
cp -R /mnt/premiumdisk/* /mnt/premiumdisk-zrs
echo "$(date) - Data migrate completed!"
touch /mnt/premiumdisk/migrated
fi
containers:
- image: jannemattila/webapp-fs-tester:1.1.20
name: storage-app
ports:
- containerPort: 8080
name: http
protocol: TCP
volumeMounts:
- name: premiumdisk
mountPath: /mnt/premiumdisk
- name: premiumdisk-zrs
mountPath: /mnt/premiumdisk-zrs
volumes:
- name: premiumdisk
persistentVolumeClaim:
claimName: premiumdisk-pvc
- name: premiumdisk-zrs
persistentVolumeClaim:
claimName: premiumdisk-zrs-pvc
volumeClaimTemplates:
- metadata:
name: premiumdisk
spec:
accessModes:
- ReadWriteOnce
storageClassName: managed-csi-premium
resources:
requests:
storage: 4Gi
- metadata:
name: premiumdisk-zrs
spec:
accessModes:
- ReadWriteOnce
storageClassName: managed-csi-premium-zrs
resources:
requests:
storage: 4Gi
But wait, we can’t update the StatefulSet directly:
$ kubectl apply -f storage-app-updated.yaml
The StatefulSet "storage-app-deployment" is invalid: spec:
Forbidden: updates to statefulset spec for fields other than
'replicas', 'ordinals', 'template', 'updateStrategy', 'persistentVolumeClaimRetentionPolicy'
and 'minReadySeconds' are forbidden
We have to delete the old StatefulSet and create a new one but luckily our disks are not deleted when we delete the StatefulSet: StatefulSets -> Limitations:
Deleting and/or scaling a StatefulSet down will not delete the volumes associated with the StatefulSet. This is done to ensure data safety, which is generally more valuable than an automatic purge of all related StatefulSet resources.
$ kubectl delete -f storage-app.yaml
statefulset.apps "storage-app-deployment" deleted
$ kubectl get pv -n storage-app
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-3d7b7320-6069-49fa-8a3c-b76c50a13aa9 4Gi RWO Delete Bound storage-app/premiumdisk-storage-app-deployment-0 managed-csi-premium 27m
$ kubectl get pvc -n storage-app
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
premiumdisk-storage-app-deployment-0 Bound pvc-3d7b7320-6069-49fa-8a3c-b76c50a13aa9 4Gi RWO managed-csi-premium 27m
Now we can apply the updated configuration:
$ kubectl apply -f storage-app-updated.yaml
statefulset.apps/storage-app-deployment created
$ kubectl get pod -n storage-app
NAME READY STATUS RESTARTS AGE
storage-app-deployment-0 0/1 Init:0/1 0 5s
$ kubectl logs storage-app-deployment-0 -c migration -n storage-app
Sat Sep 28 07:10:10 UTC 2024 - Migrate data from LRS to ZRS...
Sat Sep 28 07:10:15 UTC 2024 - Data migrate completed!
After the migration is completed, the storage-app pod is running, and the data is available on the new disk:
$ kubectl exec --stdin --tty storage-app-deployment-0 -n storage-app -- /bin/sh
/app # df -h /mnt/premiumdisk-zrs
Filesystem Size Used Available Use% Mounted on
/dev/sdd 3.9G 1.5G 2.3G 39% /mnt/premiumdisk-zrs
/app # find /mnt/premiumdisk-zrs -type f -follow | wc -l
15625
At the moment, we have two disks:
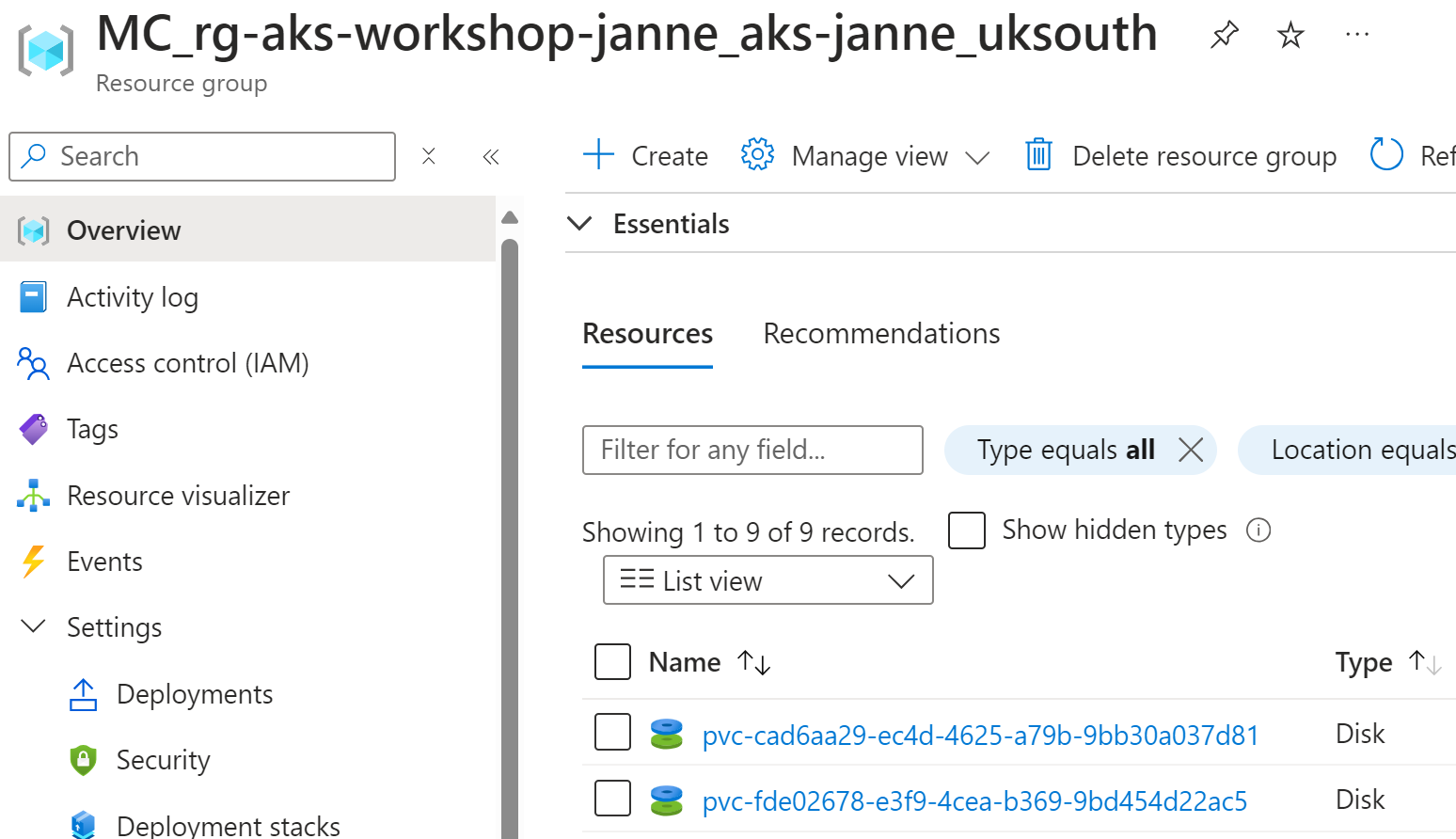
Now we need to update our configuration again to remove the references to the old LRS disk.
After that, we can delete the old disk:
$ kubectl get pvc -n storage-app
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
premiumdisk-storage-app-deployment-0 Bound pvc-cad6aa29-ec4d-4625-a79b-9bb30a037d81 4Gi RWO managed-csi-premium 11h
premiumdisk-zrs-storage-app-deployment-0 Bound pvc-fde02678-e3f9-4cea-b369-9bd454d22ac5 4Gi RWO managed-csi-premium-zrs 15m
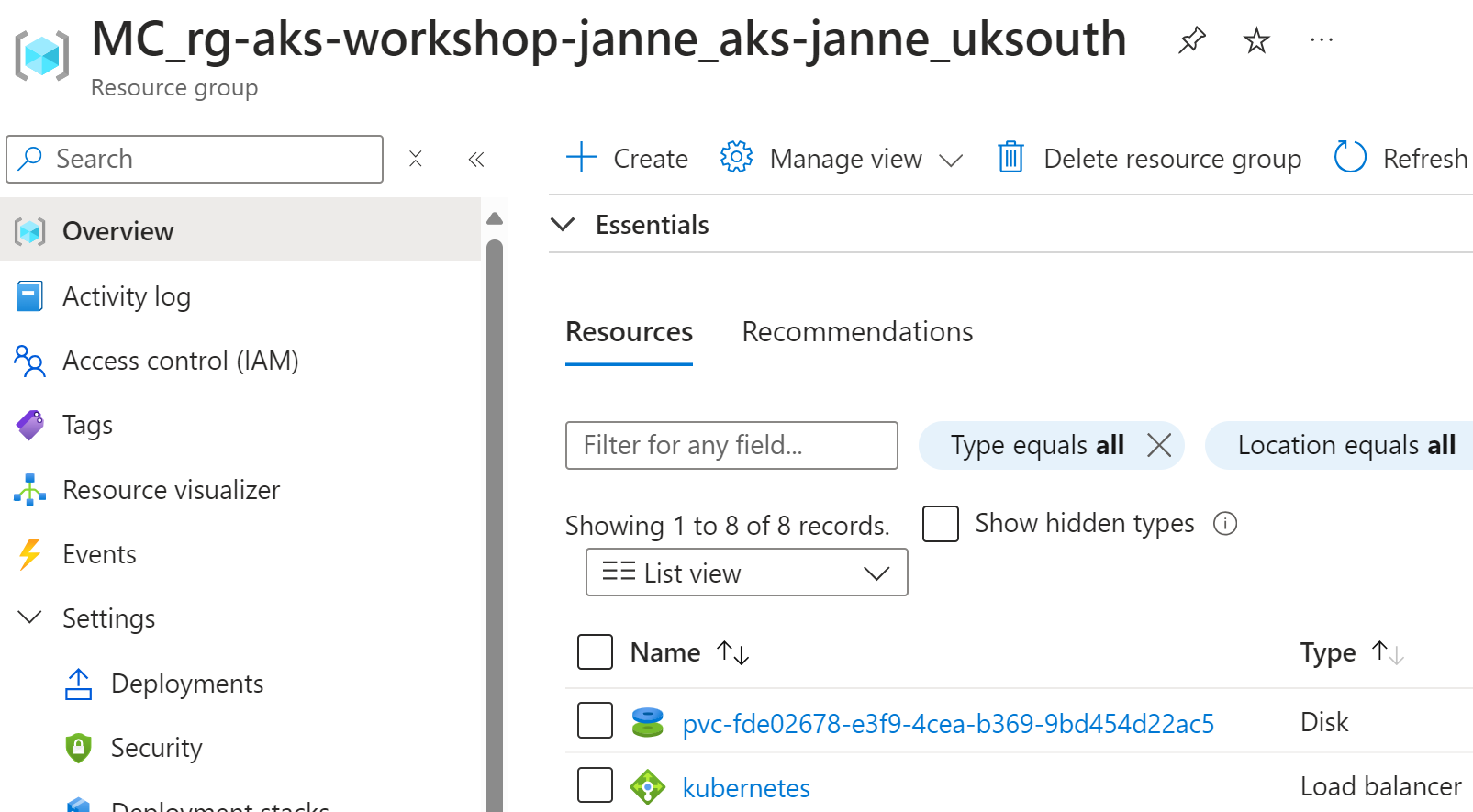
$ kubectl delete pvc premiumdisk-storage-app-deployment-0 -n storage-app
persistentvolumeclaim "premiumdisk-storage-app-deployment-0" deleted
And now we have only one disk left in our storage-app:
You can also use the Azure CLI to list the disks that are not managed by any resource. Be careful with this command since if you stop your AKS cluster, then “managedBy” will be null for all disks:
az disk list \
--query '[?managedBy==`null`].[id]' \
-g MC_rg-aks-workshop-janne_aks-janne_uksouth \
-o tsv
Did you know?
Since I happen to be writing about disks, I’ll mention this specific issue that has caused issues in the past:
Cause: Changing ownership and permissions for large volume takes much time
Conclusion
Imagine that your business-critical application is the storage-app in the above first scenario.
You thought that you were safe because you deployed your AKS cluster across multiple availability zones,
but you didn’t realize that your disks are LRS disks.
In the event of an availability zone failure, your application will be down until the node in the same zone is available again.
I have just one favor to ask: Please check disks in your AKS clusters.
And I still want to remind about my earlier post about Testing your AKS resiliency with Chaos Studio. It should give you ideas how to leverage Azure Chaos Studio for testing your applications.
The code for this post is based on this GitHub repository:
 JanneMattila/aks-workshop
JanneMattila/aks-workshop
I hope you find this useful!